
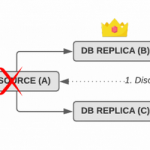
Lossless MySQL semi-sync replication and automated failover
MySQL is a really mature technology. It’s been around for a quarter of a century and it’s one of the most popular DBMS in the world. As such, as an engineer, one expects basic features such as replication and failover to be fleshed out, stable and ideally even easy to set up.
And while MySQL comes with replication functionality out of the box, automated failover and topology management is not part of its feature set. On top of that, it turns out that it is rather difficult to not shoot yourself in the foot when configuring replication.
In fact, without careful configuration and the right tools, a failover from a source to a replica server will almost certainly lose transactions that have been acknowledged as committed to the application.
This is a blog post about setting up lossless MySQL replication with automated failover, i.e. ensuring that not a single transaction is lost during a failover, and that failovers happen entirely without human intervention.

Recent Comments