
MySQL is a really mature technology. It’s been around for a quarter of a century and it’s one of the most popular DBMS in the world. As such, as an engineer, one expects basic features such as replication and failover to be fleshed out, stable and ideally even easy to set up.
And while MySQL comes with replication functionality out of the box, automated failover and topology management is not part of its feature set. On top of that, it turns out that it is rather difficult to not shoot yourself in the foot when configuring replication.
In fact, without careful configuration and the right tools, a failover from a source to a replica server will almost certainly lose transactions that have been acknowledged as committed to the application.
This is a blog post about setting up lossless MySQL replication with automated failover, i.e. ensuring that not a single transaction is lost during a failover, and that failovers happen entirely without human intervention.
Terminology & Disclaimer
This blog post uses MySQL’s new and less offensive terminology as it was introduced in version 8.0.26. We refer to primary hosts as “source” and to their replication hosts as “replicas”. Configuration parameters may still use offensive terms though.
I am a software engineer and not a DBA. Please excuse errors and let me know. I’m happy to correct any mistakes.
Asynchronous replication is best effort and will lose transactions during a failover
MySQL’s default replication mechanism is asynchronous replication, meaning that a transaction committed by the application is replicated by a background thread to all connected replica hosts. As long as the source host does not crash, this is perfectly fine. If it does, however, there are no guarantees that all transactions already made it to the replica host(s) before the crash.
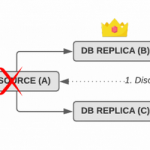
Consider a topology of three hosts, with A being the source and B and C being replicas of A:
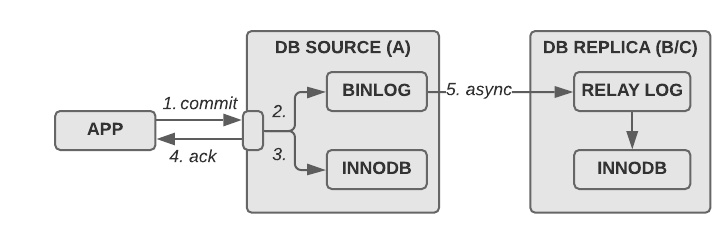
Assuming sync_binlog=1 on the source host (A), the way asynchronous replication works is like this:
- The application commits transaction to source (A)
- A writes the transaction to its binary log
- A executes the transaction in the storage engine (InnoDB)
- A acknowledges transaction to the application (What if we crash here?)
- B and C retrieve the transaction from A’s binary log, write it to their relay log via the IO thread and then apply the transaction via the SQL thread
This is obviously dangerous because the application gets an acknowledgement of a transaction before it has been replicated. If the source (A) crashes after that, the replication may not have been replicated to B and/or C and you lose transactions.
Semi-sync replication to the rescue, sort of
Clearly, asynchronous replication is not the answer if losing transactions is not acceptable for your application. Semi-sync replication solves this problem, at least partially: Unlike with asynchronous replication, the source does not acknowledge the transaction to the application until the replica acknowledges the receipt (but not the execution!) of the transaction.
Here’s how the order of operations changes with semi-sync enabled on the source and the replicas, i.e. with rpl_semi_sync_master_enabled=1 on A, and rpl_semi_sync_slave_enabled=1 on B and C:
- The application commits transaction to source (A)
- A writes the transaction to its binary log — Crash point 1: what if A crashes here?
- B and C both retrieve the transaction and write it to their relay log
- B and C acknowledge the receipt of the transaction — Crash point 2: what if A crashes here?
- A acknowledges transaction to the application
- A executes transaction in the storage engine (InnoDB)
- B and C apply the transaction in the storage engine (InnoDB)
(This example flow assumes that rpl_semi_sync_source_wait_point=AFTER_SYNC and ignores rpl_semi_sync_master_timeout and rpl_semi_sync_master_wait_for_slave_count. We’ll get to that later.)
This looks much better:
If the source crashes before the transaction has been shipped to B and C (crash point 1), our application is in a consistent state: A has not acknowledged the transaction to the application before it crashed, so it’s as if it had never been committed. As long as we fail over to B or C and don’t ever restart the source (more about that later!), we’re fine.
The other crash point (crash point 2) is more interesting: If A crashes after the transaction has been transferred to the relay log on B and C, the application will lose its database connection to A and think that the transaction failed. If we were to restart A (which we shouldn’t), the transaction would still exist in A’s binary log and it’d be rolled forward in during crash recovery. In both cases the transaction won’t be lost.
Assuming we fail over to B or C, the transaction will however still be executed there, despite the connection error. Lossless replication means we don’t lose anything, so this is actually an acceptable scenario, though incredibly unexpected from a developer perspective. We have seen these throws-error-but-still-executed cases many times, so you have to be able to deal with them.
There are obviously more than two crash points, but I think you get the idea: semi-sync replication ensures that each transaction has been written to at least one other replica before sending an acknowledgement to the application.
Dangerous semi-sync pitfalls
Unfortunately, setting up semi-sync is not as dead-simple as one might hope. There are a number of inconspicuous, yet quite consequential config parameters that you have to get just right.
Accidental fallback to asynchronous replication
The rpl_semi_sync_master_timeout parameter controls how long a source will wait on the replica(s) to respond and acknowledge the receipt of a transaction before giving up and falling back to asynchronous replication. The default value is 10,000 ms (10 seconds), meaning that in its default configuration, semi-sync replication will fall back to the best effort async replication behavior if the replica(s) don’t respond in that time.
While 10 seconds may seem like a long time for a single transaction, we all know that there are dozens of things that can cause delays like that even on modern hardware: (temporary) network failures, bad disks, or heavy load — all are reasons for why replicas could (at least temporarily) not respond within 10 seconds.
Here’s an illustration of the example above, but this time we time out (3 & 4) when trying to deliver/write to the replica. Note that the transaction is still acknowledged to the application (5), despite the downstream timeout, so if a failover were to occur now, we’d lose this transaction:

We have actually been bitten by this quite severely in one of our products: A temporary network blip caused a fallback to async replication, and a subsequent failover to a replica (also due to a temporary network failure) led to the loss of 4 seconds of transactions. That may not seem like much, but it took us multiple days to repair the affected tables.
If you want to make sure that you never fall back to asynchronous replication, you must set rpl_semi_sync_master_timeout to something outrageously high, e.g., one hour or even 24 hours.
While this will guarantee that transactions won’t get written to the source without being at least received by one replica, the implication is that if your replica(s) are down (even just for maintenance), your application will block “forever”. This is a desired state if your most important requirement is not losing a single transaction, but still something that may not be entirely clear to administrators or developers when setting up semi-sync replication.
(Note that there is a way to avoid the forever-blocking nature of semi-sync using two replicas, and dynamic semi-sync flag management using orchestrator. I’ll talk about this further down.)
Promotion confusion due to incorrect replica count
The rpl_semi_sync_master_wait_for_slave_count config option controls how many replicas MySQL will wait for before acknowledging the transaction to the application. The default value is 1, meaning that even if you have two configured semi-sync replicas, MySQL will only wait for one of them to respond before assuming that things are fine.
Assuming our three host example above has rpl_semi_sync_master_wait_for_slave_count=1 set, we won’t know if B or C acknowledged the transaction. As long as the source (A) doesn’t crash this is not a problem, of course. If A crashes, however, our failover script (or our topology manager) has to decide which replica to fail over to and promote to be the new source: B or C.
Depending on the sophistication of the failover script or the topology manager, it is of course possible to figure out which replica has received the latest transactions (using GTIDs and/or the binary log position), but it makes the whole scenario much more complex.
For our setup, we have chosen to enable semi-sync on only one of the replicas and never promote the second asynchronous replica. This can be achieved with orchestrator’s brand new EnforceExactSemiSyncReplicas option (see below).
Re-using a failed source
Even though the semi-sync documentation clearly states that you should never re-use a failed source, I feel obligated to repeat it here, because the implications of re-using a failed source are quite significant.
Here’s what the docs say:
“With semisynchronous replication, if the source crashes and a failover to a replica is carried out, the failed source should not be reused as the replication source, and should be discarded. It could have transactions that were not acknowledged by any replica, which were therefore not committed before the failover.“
This paragraph talks about the crash point 1 scenario from above. When a transaction is written to the binary log on the source (A), but it didn’t make it to B or C, this transaction officially never happened from the application perspective and from the perspective of B and C.
If you now re-use A (even as a replica of B or C), there will be a renegade transaction in A. In the best case, A won’t start up properly. In the worst case, you won’t notice for a while, but the state of source and replicas won’t be identical.
Bottom line: Don’t ever re-use a failed source. Rebuild it using xtrabackup from the promoted new source.
Automated failover is hard
While replication is part of MySQL’s core feature set, topology management and automated failover is not. What that means is that in the case a source host goes down, or has to be taken down for maintenance, MySQL won’t decide on a new source, change replication targets and it certainly won’t tell your application which of the replicas the new source host is.
To achieve an automated failover from a failed source to a replica, you have to employ the services of other tools. Unfortunately, the tool landscape for MySQL failover has changed over the years and it’s still a little bit of a wild wild west out there.
keepalived, VIPs and roll-your-own scripts: not for lossless failover!
For a very long time, we were using a failover mechanism that was based on keepalived, a floating virtual IP address (VIP) and some custom monitoring and failover scripts.
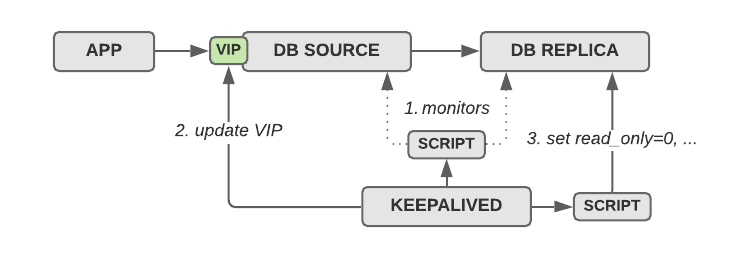
In this setup, the application talks to the MySQL source host via a floating IP address, which is controlled and managed by keepalived. Each MySQL host runs keepalived, which regularly runs a monitoring script that performs basic checks (1). If the health check of the MySQL source fails, it moves the VIP to the replica host that will become the new source (2) and then (!) triggers a notify script which will flip the host to read/write to become the new source (3).
This setup actually works quite well, requiring few moving pieces and no extra hosts. However, in our experience it is much less robust than a proxy based setup and not suitable if you require lossless failover with semi-sync. Here’s a (non-exhaustive) list of issues we ran into:
keepalived doesn’t know anything about MySQL. It just manages a VIP and isn’t aware of the MySQL topology. It doesn’t know who the source is, what the read_only flag is set to or if semi-sync is enabled. All of that has to be done by you in your own scripts. Not only is that a lot of work, it is also prone to error. You have to manually implement a mutex lock to make sure only one script runs at a time, you have to implement waiting for the relay logs to be processed, fencing, and you have to manually flip the read only and semi-sync state. Lots to do, lots to go wrong.
keepalived is decentralized. It works by all participating nodes communicating with one another. What that means is that if the communication between the nodes is (even momentarily) interrupted, there is a significant risk of split-brain and with that, the risk that two nodes will try to grab the VIP and declare themselves the source with read_only=0. While the network layer will obviously ensure that only one host has the VIP, it could still flap back and forth between the hosts. The consequences of that are quite catastrophic, as it can lead to two MySQL hosts applying transactions. The perfect storm.
I could go on, but I’ll leave it at that. We had lots of trouble with this solution when we really started playing Chaos Monkey so I advise against this if you like your data.
HAproxy/ProxySQL, orchestrator, Consul and Consul Template
Luckily, there are a few popular setups out there that work quite nicely and don’t experience the above mentioned problems. Pretty much all of them revolve around using a combination of ProxySQL or HAproxy, orchestrator, Consul, and Consul Template. There are a number of great resources (4 links!) out there describing them, so I’ll be brief.
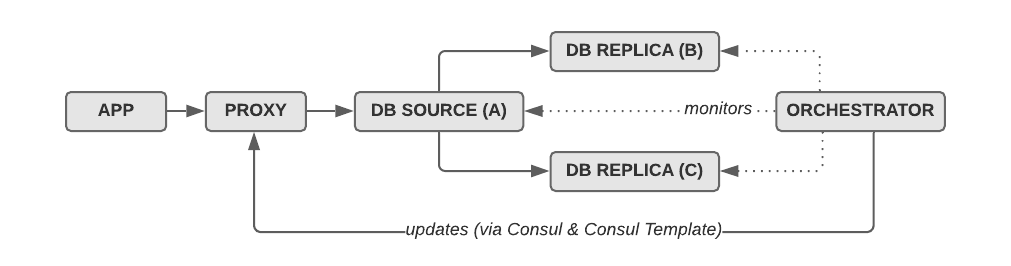
(Note that in this illustration, “proxy” can be HAproxy or ProxySQL. See below for details.)
All of the linked setups rely on monitoring the MySQL hosts for their health (responsiveness, replication, lag, …) using the topology manager orchestrator, and proxying SQL traffic through either HAproxy (TCP-level proxy) or ProxySQL (application-level proxy) to the current MySQL source host.
When orchestrator detects a failure on the source host (A), it first determines which of the replicas will become the new source, either B or C. Once it has figured that out, it repoints MySQL replication (stop slave; change master to …; start slave) of the remaining hosts and isolates the failed source (A). After that, it tells the proxy (HAproxy or ProxySQL) to repoint to a different host. In the most popular setup, this happens by dynamically updating the configuration through Consul and Consul Template.
Dangerous failover pitfalls
Even more so than setting up MySQL semi-sync replication, setting up failover as described above is quite tricky. There are lots of tools involved, and naturally each of them have tons of configuration options. Many things to do wrong.
Always wait for the relay log before accepting write traffic
Semi-sync replication guarantees the delivery of a transaction to the replica(s), but not the execution. It makes sure that the relay log on the replica(s) has a copy of every transaction, but still handles the execution asynchronously.
That means that it is very easy for MySQL replicas to fall behind on the execution of transactions and create a replication lag, if the SQL thread cannot execute transactions fast enough in the storage engine (7).
That’s why it’s called semi-sync replication, and not synchronous replication. (It sure would be nice if it was fully synchronous, though.)
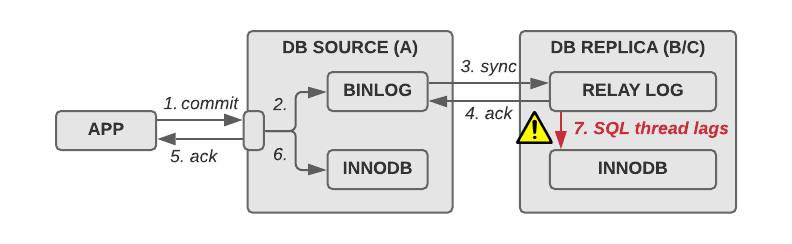
If you develop your own failover solution, it is vital that you ensure that you fully process all existing relay logs on the replica that has been designated the new source before turning on write traffic, i.e. before setting read_only=0. If you don’t, you’ll start writing transactions to the storage engine out of order. In the best case scenario they will be unrelated, but most likely you’ll get pretty horrible duplicate key exceptions and will spend hours or days trying to repair the state.
When using orchestrator, waiting for the relay logs can be enabled by setting DelayMasterPromotionIfSQLThreadNotUpToDate=true. Since orchestrator manages the read-only state, you don’t have to worry about that separately.
Be sure to shoot the other node in the head
There are many different failure modes that may lead to the decision to fail over to a replica. For the sake of simplicity, we as engineers often only talk about a hard crash of a source and sometimes forget that temporary failures such as network blips, a hanging process or even just a service restart. Not considering temporary failures like this can be a huge mistake, because we always want to make sure that our application is only ever talking to the correct source, and not to the back-from-the-dead host that we failed over from.
When the decision is made to fail over from a failed source to a newly promoted replica, it is important to fence off the failed node from the application before appointing a replica to be the new source. This process is called Shoot The Other Node in the Head (STONITH).
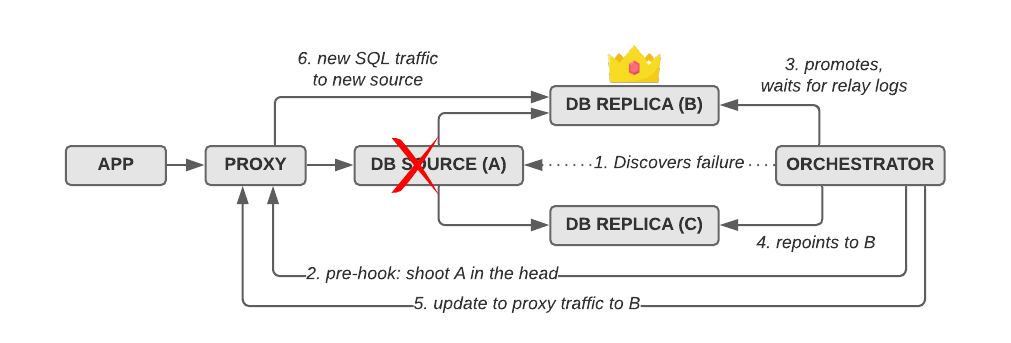
Here’s an example of a failover with orchestrator that includes a STONITH pre-hook:
In this illustration, we see orchestrator has discovered a failure on the source (A) and decides to fail over to B. Using orchestrator’s pre-failover hook PreFailoverProcesses, we fence off A by pointing the proxy to “nowhere” while the failover is in progress. After orchestrator has completed the failover to the new source B (3), and repointed the other replica C to the new source (4), it updates the proxy configuration again (5) to send traffic to the new source (6).
Without the STONITH step (2), the proxy would point to the failed source until orchestrator is done with the failover. If the host comes back online in the meantime, you will have written to the wrong source host, and in the worst case you’ll lose those transactions.
Unfortunately, orchestrator does not support STONITH out of the box, so you’ll have to write your own pre-hook script to accomplish it. In HAproxy, you can simply update a listen block to point to 127.0.0.1:1337 (a non-existing target). In ProxySQL, you can achieve this by marking the host as OFFLINE as this blog post describes.
(Please note that the STONITH approach is not without controversy. You may read more in this blog post.)
Putting it all together
As of today, we’ve deployed our lossless semi-sync setup and the automated failover solution on hundreds of hosts, managing hundreds of millions of tables. Despite a few (quite severe) hiccups and the hundreds of hours we’ve spent optimizing and automating things, I’d say overall we’re pretty happy with the setup.
We’re using the exact setup I already talked about, namely HAproxy, orchestrator, Consul and Consul Template. I’ve uploaded a representative set of configuration files to GitHub, so you don’t have to start from zero when setting this up yourself.
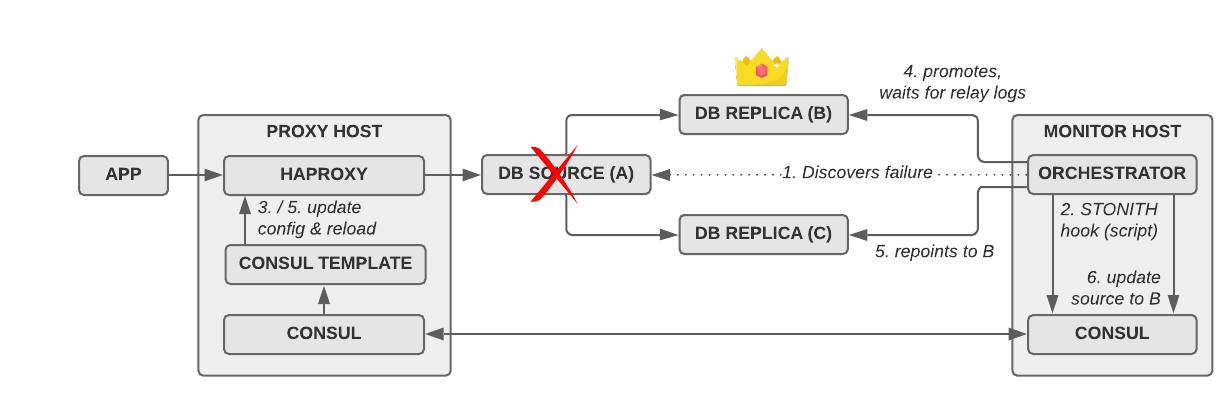
Here are some details and important configurations:
MySQL:
We use Percona Server 8, which works pretty well, despite the extreme scale that we use it with. We’ve seen a number of horrible crashes related to too many replication restarts (which we fixed by telling orchestrator not to restart replication so often through a higher ReasonableReplicationLagSeconds setting), but other than that I’d say it’s been solid.
The semi-sync settings in our mysqld.cnf file match what was discussed above. Long source timeout to prevent async fallback, and semi-sync enabled by default:
|
1 2 3 4 |
loose-rpl_semi_sync_master_enabled = 1 loose-rpl_semi_sync_master_timeout = 3600000 loose-rpl_semi_sync_slave_enabled = 1 loose-rpl_semi_sync_master_wait_for_slave_count = 1 |
It is worth noting that if you enable the semi-sync source setting on all hosts (including replicas) at startup, you may run into oddities in your stats. We solved this with a custom script (not in the repository) that disables the setting on replicas dynamically (rpl_semi_sync_master_enabled=0).
HAproxy:
After an unsuccessful attempt to use ProxySQL (it kept crashing constantly), we decided to use HAproxy for proxying SQL traffic to the currently active source host(s). The main haproxy.cfg file is pretty basic and not really worth talking about.
The mysql.cfg file, however, contains listen blocks that route to the currently active source hosts. This file is autogenerated and kept up-to-date by Consul Template using the template file haproxy_mysql.cfg.tpl. The template will generate a listen block like this for every MySQL source host:
|
1 2 3 4 5 |
listen mysql-g0 bind 10.0.13.1:3400 server db-g0-1.example.com 10.0.14.1:3306 mode tcp option tcplog |
It also implements one part of our STONITH approach: If the Consul key mysql/master/$cluster/failed exists, it will black-hole all traffic to this cluster by pointing it to 127.0.0.1:1337, a non-existing host.
Consul Template:
The template above is updated and re-rendered by Consul Template using the config file haproxy.hcl. After it re-renders the file, we reload HAproxy to refresh the configuration.
In our real production environment, we don’t just call out to systemctl reload haproxy. Instead we have a tiny Python script (not included in the repository) that kills all active connections to the cluster and then reloads HAproxy.
Consul:
Consul is the single source of truth for which MySQL host(s) are the source. The installation is pretty straightforward (see configuration files).
orchestrator:
We run orchestrator in a cluster of three with a MySQL backend and with Raft support (see configuration files).
Most importantly, we enabled DelayMasterPromotionIfSQLThreadNotUpToDate=true, which makes sure that orchestrator waits for the relay logs before promoting a replica and turning read-write on. See above for a detailed discussion on this.
We also enabled the brand new EnforceExactSemiSyncReplica=true setting (which I am very proud to have contributed to orchestrator), which completely manages the semi-sync replica state: with this setting, orchestrator will enforce the correct semi-sync flag on the replicas during failover (i.e. enabling and disabling it), matching the wait count set in rpl_semi_sync_master_wait_for_slave_count. For us this is especially important, because we’d like to only ever have one semi-sync replica, even though we have two replicas, so that we know which host to fail over to, and so can do maintenance or one of them can crash.
Looking at the PreFailoverProcesses in the orchestrator.json file, you can see that we’re calling a script called orchestrator-pre-failover (not included in the repository). This script sets the mysql/master/$cluster/failed key, which triggers Consul Template to update the HAproxy config and back-hole the cluster for new traffic. This is the other side of the STONITH mechanism I talked about above.
Wrapping it up
As you can tell from the length of this post, our journey to lossless MySQL replication and failover has been quite interesting and we’ve learned a lot. If you’ve read the whole thing, I applaud you and thank you for staying with me.
In this post, I discussed all the technologies and tools that are necessary to provide a MySQL replication environment with lossless automated failover. I compared async replication to semi-sync replication and discussed some gotchas. I then presented different approaches for automated failover and highlighted the pieces that are relevant for a lossless setup, concluding in a section showing our own fully functional setup.
MySQL replication and failover is complicated. It’s really easy to mess it up and lose data. I hope this post helped prevent data loss in your organization.
Recent Comments