

Deep into the code of Syncany – command line client, application flow and data model (part 2)
I recently published a blog post about my open source file sync project Syncany. I explained the main idea of the project and also went into some of the details about where the development is headed. The post was the first of a series I am planning to write — showing what the project is about from different angles.
While the first post had a few technical elements, it mostly discussed the project’s process and its high level goals and ideas. In this second article, I’d like to go beyond the high level concepts and go a lot deeper into the different packages and modules of the software. Why, you ask? Because I think it might be interesting of others and because I believe that supporters and other developers will benefit from it.
Content
1. Overview
The post references concepts of the current code as of February 2014. Over time, some of the classes/concepts might change. For that reason, I’ll be linking to a specific revision of the code.
2. Similarities and differences to other tools
As stated in other posts, the fundamental idea of the Syncany software architecture is a mixture between a version control system like Git, SVN or Bazaar, a file synchronization software like rsync or Unison, and crypto software such as GPG.
Like in a version control system (VCS), Syncany keeps track of the files in a certain folder using metadata about these files (size, last modified date, checksum, etc.). It manages different versions of a file, detects if a file has been moved or changed and adds a new file version if it has. Like version control systems, Syncany knows a concept similar to a “commit”, i.e. a collection of changes the local files that are uploaded to the central repository. In other ways, however, it is also very different: In contrast to Git and its friends, Syncany does not support the full range of commands that regular VCS do. For instance, there is no explicit branching or merging, no tagging and diffing. Instead, Syncany has only one trunk/master and auto-resolves conflicts when they occur (much like Dropbox does). Unlike most VCS, Syncany does not focus on text-based files, but treats all files the same (large/small, binary/text). In addition, Syncany is not limited to one or two transport protocols, but can be easily extended to many more.
The similarities to file sync software are quite obvious: Syncany must tackle the file synchronization problem, i.e. the problem of keeping multiple replicas of a file set in sync. Much like the widely popular rsync, Syncany compares the local files to the remote copy (or at least its metadata) using date/time/size and checksums of both whole files and parts of files, and then transfers only the changed parts to the remote location. Like rsync, Syncany tries to minimize the individual upload/download requests (and the corresponding network latency) by grouping these changes into bigger blocks. However, while rsync does that by actively gathering the file stats on the remote system, Syncany only uses the downloaded metadata, i.e. using dumb storage is possible.
Unlike any of the above mentioned tools, Syncany is built with and around cryptography and takes confidentiality and data integrity very seriously: Syncany generally assumes that everything but your local machine can be monitored/eavesdropped by others which is why it encrypts all data locally before uploading. As of now, Syncany only supports password-based symmetric key encryption based on configurable ciphers. By default, it uses 128 bit AES and Twofish, both in the authenticated GCM mode, but basically can support anything that Java and the Bouncy Castle crypto provider have to offer.
3. Command line interface (CLI)
The current code (as of February 2014) only focuses on a command line version of Syncany, but makes the main operations usable by any user interface. So don’t be alarmed if the following mainly describes the command line client. A GUI will follow soon enough. In fact, Vincent Wiencek already started working on a SWT-based GUI (was at: https://github.com/vwiencek/syncany/commits/gui, site now defunct, July 2019) that already looks pretty neat.
To understand the following chapters, it is very useful to understand the intended usage of the tool. The basic syntax is very similar to a version control system:
- sy init: After interactively asking the user about the desired storage backend (e.g. FTP, Amazon S3) and the password, this command first creates the local configuration in .syncany/config.xml (local machine name, password), as well as a .syncany/repo file (containing chunking/crypto details). The latter file is uploaded to the repo to initialize the remote repository.
- sy connect: To connect to an existing repository (= any storage with a repo file), this command can be called. It basically also creates a local config like the sy init command, but downloads the repo file from the storage. To make connecting to an existing repo easier, we created the concept of a syncany://-link — a password-encrypted string containing the storage-plugin settings (e.g. FTP host/user/pass/…).
- sy status: Once a client is set up (using sy init or sy connect) and local files have been added to the local folder, the sy status command shows the locally changed/unknown/deleted files.
- sy ls-remote: The ‘list remote’ command queries the remote storage and lists the client database versions (~ “commits”) that have not yet been downloaded/processed.
- sy up: This command is the first part of the magic. Using the input from sy status, it breaks the locally changed files into individual 16 KB chunks, calculates a checksum for each chunk and compares this checksum to the local database. If the chunk does not exist, it is packed into a multichunk with other chunks and uploaded to the remote storage. In addition to that, the metadata (added/changes/deleted files, their chunks and checksums) is added to a new database version and also uploaded. When comparing this command to other VCS (like Git), it is similar to git add . and git commit.
- sy down: And this is the second part of the magic. This command downloads the new client database versions (as identified by sy ls-remote) and compares them to the local database and the local file system. Using vector clocks, a winning branch (= list of database versions) is determined and finally applied to the local file system. File conflicts are resolved automatically by renaming locally conflicting files as ‘conflicting’ (like Dropbox).
There are a few other commands, but they are basically just orchestrations of the above mentioned commands. Especially the latter four commands are incredibly important to fully grasp the concepts.
4. Software architecture
4.1. Application flow
Much of the basic architecture can be easily explained by the commands above. However, to make it a bit easier, I tried to illustrate the usage of these commands in a high level sequence diagram (the image is only shows an excerpt; click on it to show the full-size diagram):
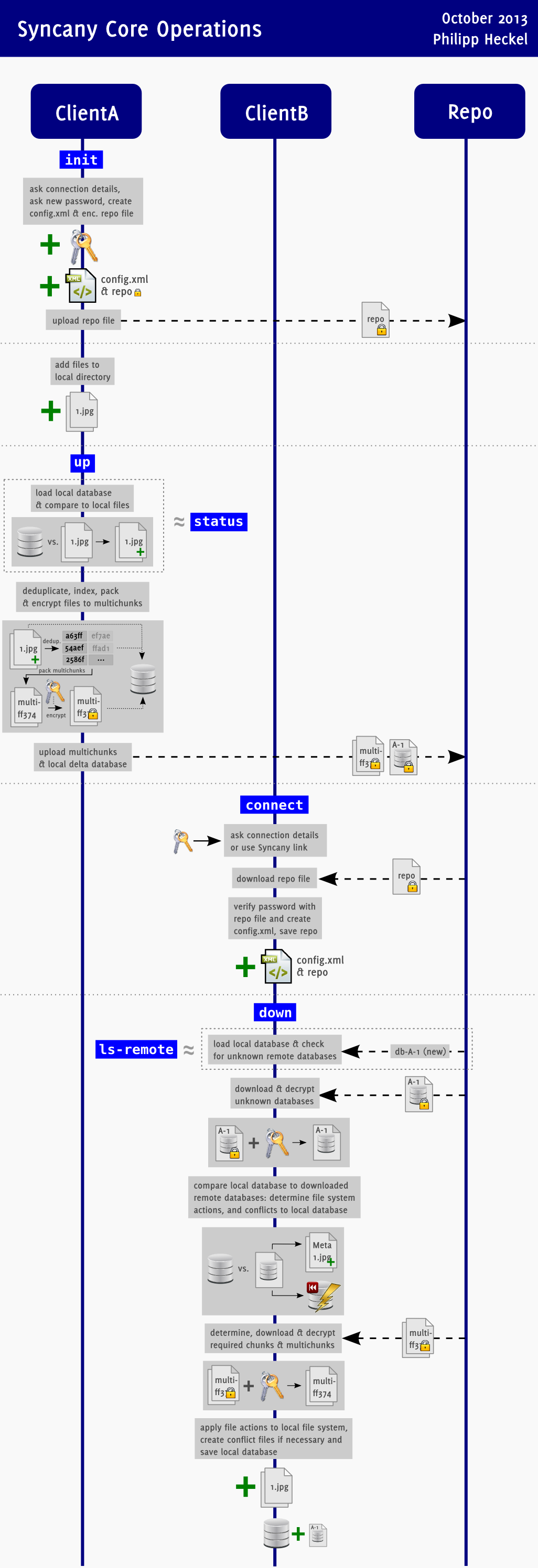
Actors: The sequence diagram’s swim lanes represent the different actors/systems involved in the synchronization process. In this example, there are two clients (Client A and Client B) who both have Syncany installed on their machine. These can be server machines or just regular laptops. They have replicas of the synchronized files in their local Syncany folders (e.g. at “C:\Users\ClientA\Syncany”).
The system labelled Repo is a dumb storage — for instance a folder on an FTP server, an Amazon S3 bucket or a WebDAV folder. It stores the encrypted/packaged files and some metadata about them.
Client A initializes the repo and adds a file: In the example, Client A initializes the repository locally using the init command (has to be done only one time), adds an image to its local Syncany folder (here: 1.jpg) and then calls the up command to index and upload these files to the repo. As you can see in the diagram, the status command and the up command do the main work: the two commands walk through the file tree of the local Syncany folder and compare the files on the disk with the local database. If there is a difference (e.g. new/deleted/renamed files, changes in file mod. times, etc.) these changes are recorded and uploaded.
This happens in two steps: First, the metadata of each file is analyzed (modified date, size) to see if anything has changed. If something has changed, the new/changed files are broken into chunks using a chunker (e.g. a fixed size chunker). New chunks, i.e. chunks that did not appear in other files, are packed into multichunks (= ZIP files with many chunks), encrypted and uploaded to the repo. To be able to reconstruct the files (and to track the file tree history), additional incremental metadata is also uploaded (db-* files).
Any other client can now connect to the repository, download the metadata (and its relevant multichunks) and reconstruct file tree.
Client B connects to the repo and downloads all changes: In the example, Client B does just that: Using the connect command, the client first downloads the repo file and sets up the local Syncany folder (like the init command, this has to be done once).
Once this is done, files can be synced with the other clients by calling the down/up commands. In the example, the down command is called to retrieve (and apply) all the changes of the other clients. Since this is the first contact to the repository, all of the other clients’ files (here: only 1.jpg of Client A) must be downloaded. To do that, the down command first uses the ls-remote command to determine whether there are new metadata files (db-* files). If there are, they are downloaded and compared to the local database.
In the example, the metadata file db-A-1 is unknown/new and must be downloaded and decrypted by Client B. After that has been done, the changes that are described in the metadata file are compared to the local database in order to determine necessary actions on the file system. Such actions might be “change last mod. date of file 123.bmp to rw-rw-r–” or “delete file 123.bmp”. In this example, the only action is “create file 1.jpg”.
For actions that require actual chunk data (e.g. creating/changing files, but not deleting files) the relevant multichunks are downloaded and decrypted, and the file system actions are applied to the local disk. After that, the local database is updated and both clients are in sync. In the example, the file 1.jpg contains only chunks that are stored in the multichunk multi-ff374, so only this multichunk is downloaded and decrypted. Using this multichunk, the down command then reconstructs 1.jpg.
That was of course an easy example, but that’s pretty much how Syncany works internally. Some of the more interesting parts (e.g. conflict handling) is described below.
4.2. Internal data model
One of the most important things to understand is the structure of Syncany’s internal data model. Everything revolves around this model, so it’s essential that you understand it if you want to be able to grasp the rest of the system.
Syncany’s data model consists of only a handful of entities — all of which are present in the form of Java POJOs, tables in the local HSQLDB-based database, as well as serialized in the XML-based metadata files.

Main idea: The entities in the data model represent the file tree of a single Syncany folder throughout its lifetime. It combines the concepts of versioning, deduplication and multichunking.
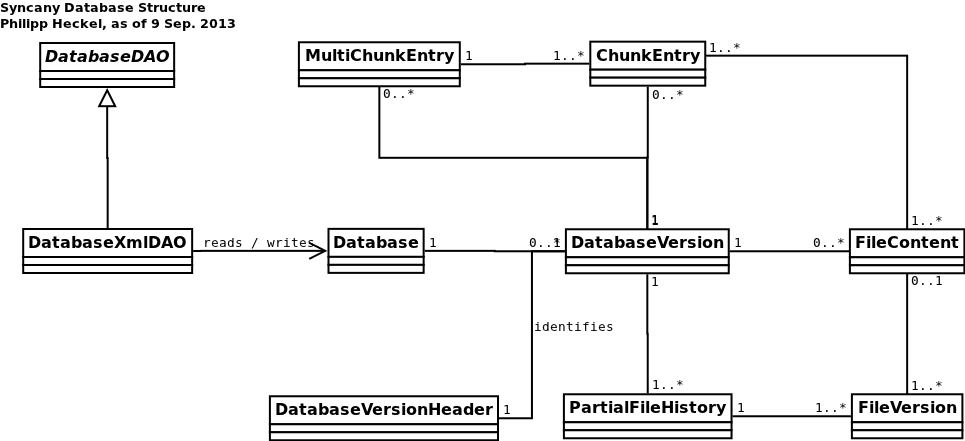
- Versioning: Syncany not only capture the current version of a file, but instead captures many versions of a file — much like a version control system. So if a file “1.jpg” is changed or moved, Syncany stores the new file as a second version of the first file, but at a later time. In the data model, this is captured by the concepts of database versions, file histories and file versions. A database version represents the point in time at which the file tree is captured. It contains a list of file histories. A file history represents the identity of a file, and the file versions for each file history represent the incarnations of a file. Each file history can contain one to many file versions. In the above example, the file history for the file “1.jpg” will contain at least two file versions — the initial file version and the changed/moved file version.
- Deduplication/Chunking: Syncany breaks individual files into small chunks (data blobs) and keeps a list of chunks per file version in a the entity file content. Each of these chunks can belong to many file content entities and each file content can belong to many different file versions.For example: Two files “1.jpg” and “2.jpg” may have the same file content, consisting of the same chunks — say, chunkA, chunkB and chunkC. These three chunks together are grouped to a file content with checksumABC. When “2.jpg” is changed by a few bytes, its file content also changes (new checksum), but most of the chunks will stay the same — say, to chunkA, chunkB and chunkZ. The new file content might have the checksumABZ.
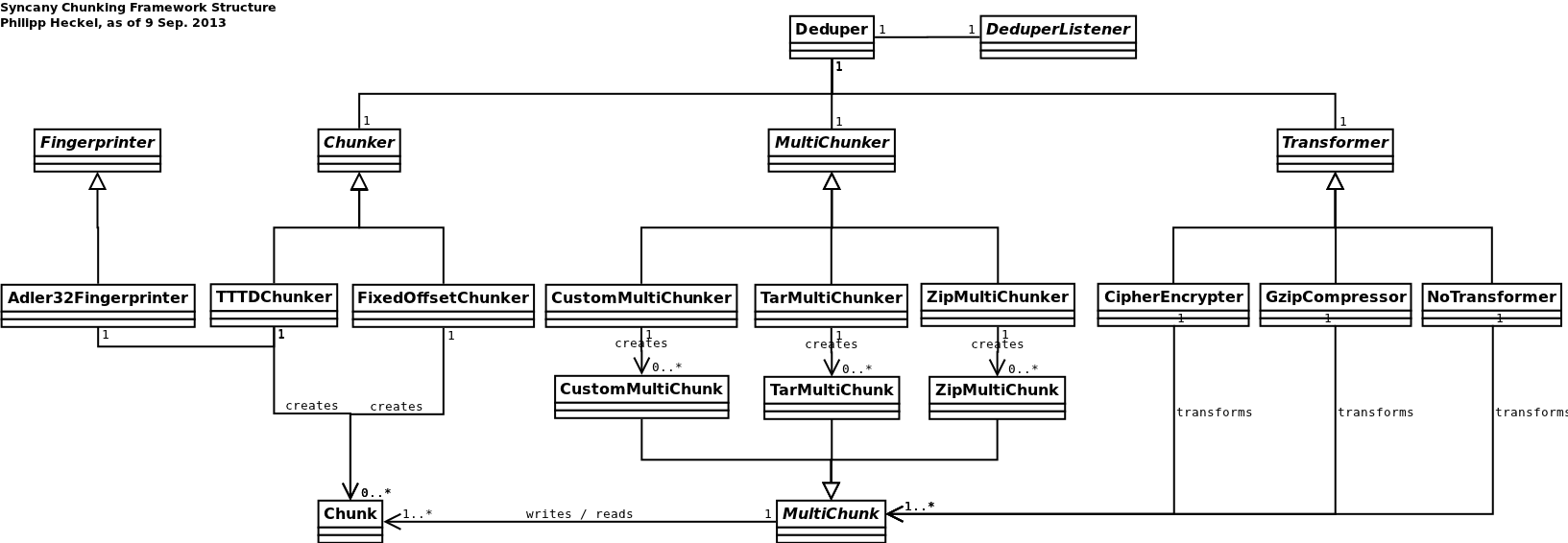
- Multichunking: In addition to the association to one or many file content entities, a chunk is always associated to a multichunk. Multichunks are the containers in which the chunks’ actual data is stored — basically a ZIP file containing many chunk entries. The multichunks are stored on the remote repository.
4.2.1. Data model in Java
As indicated above, these entities are also represented in Java POJOs in the org.syncany.database package. The POJOs are filled by a few data access objects (DAO) from the HSQLDB database (in the Syncany folder at .syncany/db/local.db). Whenever a delta database (= one or many database versions) has to be uploaded, they are persisted in an XML file (on the remote repository at databases/db-*).
In short, the following Java classes are the most relevant:
- DatabaseVersion: A database version is similar to a commit in a version control system. It contains zero to many instances of PartialFileHistory, FileContent, ChunkEntry and MultiChunkEntry. These objects make up the entire metadata saved to each file. They are used to reconstruct files on the different clients. Each database version is identified by a header, consisting of the owner’s machine name, a vector clock the local timestamp of when the database version was created. This header is largely used in the synchronization algorithm.
- PartialFileHistory and FileVersion: To allow restoring lost or altered files, Syncany tracks and records many versions of each file. Each of these versions (captured in FileVersion objects) consists of the file metadata at a particular time. Among others, Syncany records (and syncs): version number, path, type, size, last modified date, checksum, permissions/attributes and link target (for symlinks). The collection of all of these versions is a file history. And because file histories are mostly spread over different file versions, the class is called PartialFileHistory.
- FileContent: Identified by the checksum in the FileVersion, the FileContent class references the list of data blocks (ChunkEntrys) that make of the content of a file. Multiple file versions can reference the same file content (similar to hard-linking on some file systems).
- ChunkEntry: Syncany breaks files into individual chunks (see chunking chapter) and only stores each chunk once. A chunk is identified by its checksum and represented by the ChunkEntry class.
- MultiChunkEntry: To reduce network latency and improve transfer performance, Syncany groups individual chunks into multichunks (like a container or archive). The MultiChunkEntry object identifies these containers/archives and lists all the contained ChunkEntrys.
If you want to check out the actual code, feel free to browse through the org.syncany.database package on GitHub.
4.2.2. Data model in HSQLDB
The local SQL database is used to speed up the performance of queries to the database. We recently switched this from a memory-only model (XML-to-POJOs), because queries on Java objects (especially with this many lists) are unbearable and very slow.
Here’s a diagram of the HSQLDB tables (including all column definitions):
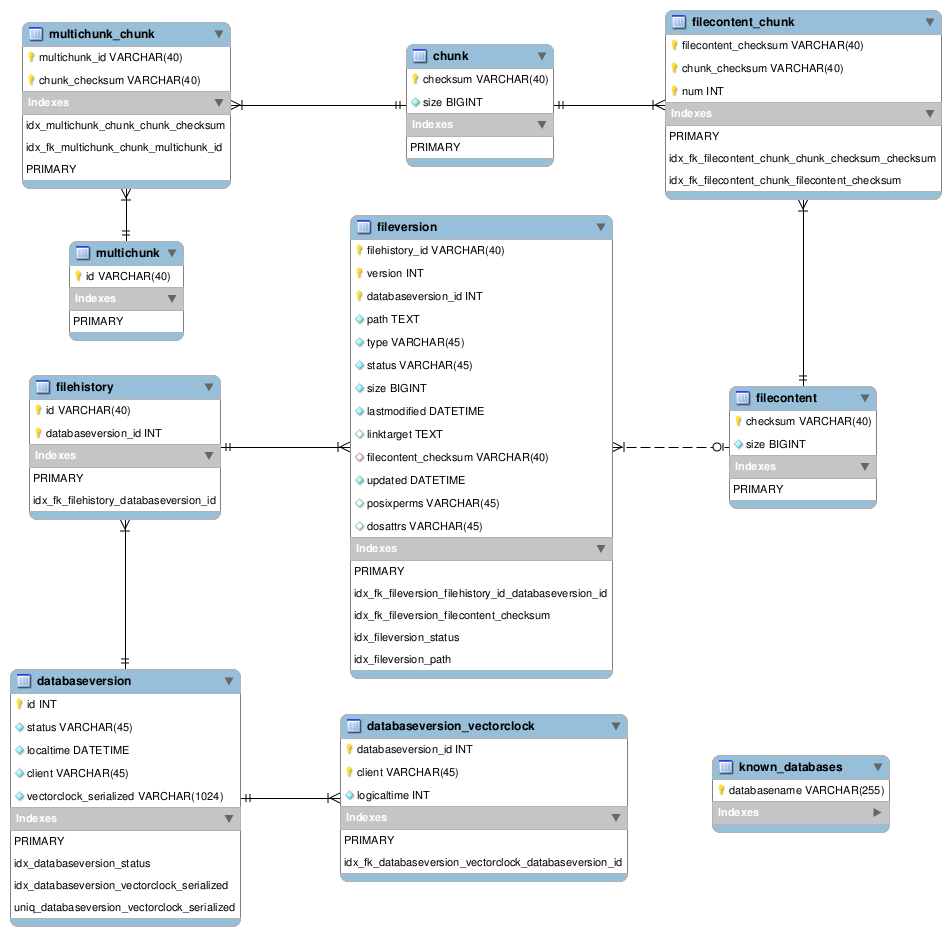
Note that although the diagram is made with MySQL Workbench, HSQLDB is used an embedded database backend.
4.2.3. Data model in XML
As mentioned above, the data model is also persisted to XML in order to exchange the metadata with other clients. It follows the same logic as in the Java POJOs and the SQL database.
The example file below contains four database versions. Here’s an excerpt of the file (complete database file here):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 |
<database version="1"> <databaseversions> <!-- ... ---> <databaseversion> <header><!-- ... --></header> <chunks> <chunk checksum="38b762b5b9f9276e050d47e4baec3e98008d7cfe" size="16"> </chunk></chunks> <multichunks> <multichunk id="c784d4a71e55f69e40a3c39dd1cf8a70a57b20dc"> <chunkrefs> <chunkref ref="38b762b5b9f9276e050d47e4baec3e98008d7cfe"> </chunkref></chunkrefs> </multichunk> </multichunks> <filecontents> <filecontent checksum="38b762b5b9f9276e050d47e4baec3e98008d7cfe" size="16"> <chunkrefs> <chunkref ref="38b762b5b9f9276e050d47e4baec3e98008d7cfe"> </chunkref></chunkrefs> </filecontent> </filecontents> <filehistories> <filehistory id="-7025940221195530663"> <fileversions> <fileversion version="2" type="FILE" status="CHANGED" path="newfile.txt" size="16" lastmodified="1383948589000" createdby="platoppheckel1044278922" updated="1383948593656" checksum="38b762b5b9f9276e050d47e4baec3e98008d7cfe" posixperms="rw-rw-r--"> </fileversion></fileversions> </filehistory> </filehistories> </databaseversion> <databaseversion> <header><!-- ... --></header> <chunks> <chunk checksum="77c2e212cd85bcbd2dc39e0848c09a4d169e2b3e" size="36"> </chunk></chunks> <multichunks> <multichunk id="520d8087c169cf77b79a22afc1ae0ad3942f1aab"> <chunkrefs> <chunkref ref="77c2e212cd85bcbd2dc39e0848c09a4d169e2b3e"> </chunkref></chunkrefs> </multichunk> </multichunks> <filecontents> <filecontent checksum="77c2e212cd85bcbd2dc39e0848c09a4d169e2b3e" size="36"> <chunkrefs> <chunkref ref="77c2e212cd85bcbd2dc39e0848c09a4d169e2b3e"> </chunkref></chunkrefs> </filecontent> </filecontents> <filehistories> <filehistory id="-7025940221195530663"> <fileversions> <fileversion version="3" type="FILE" status="CHANGED" path="newfile.txt" size="36" lastmodified="1383948619000" createdby="platoppheckel1515986815" updated="1383948620802" checksum="77c2e212cd85bcbd2dc39e0848c09a4d169e2b3e" posixperms="rw-rw-r--"> </fileversion></fileversions> </filehistory> </filehistories> </databaseversion> <!-- ... ---> </databaseversions> </database> |
4.2.4. Data model example
The following example will show how the data model behaves over time. Hopefully, it will also make it easier to understand the chunking/versioning concept that I described above.
Feb 13, 9:03pm:
Client A’s Syncany folder contains one folder “Docs” and a file “1.txt” inside this folder. It basically looks like this:
- Docs/
- Docs/1.txt
The user calls the sy up command to index and upload the local changes. After that, the internal logical data model looks something like this:

This information is stored in the local HSQLDB database as well as on the remote storage (XML-format, see above). Because this is the Client A‘s first database version, it is uploaded to databases/db-A-1 on the remote repository (e.g. on the FTP, WebDAV, etc.). Also, because the database version contained new chunks, the new multichunk e11f... is uploaded to multichunks/multichunk-e11f... on the remote repository.
Feb 13, 9:04pm:
The user then renames “1.txt” to “2.txt” and adds a new file “3.txt”. The file “3.txt” partially consists of the same content as “2.txt”. So the file list looks like this:
- Docs/
- Docs/2.txt
- Docs/3.txt
Again, the user calls sy up to index and upload the local changes. After that, the logical database representation looks something like this:
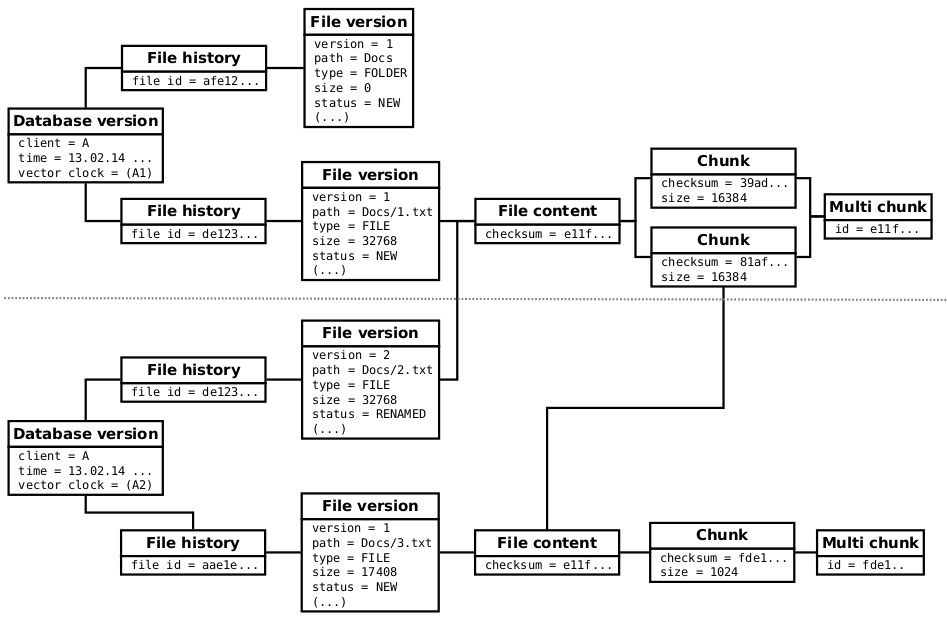
The new database version (below the dotted line) is persisted to the local HSQLDB database and uploaded to databases/db-A-2 on the remote repository. The new multichunk fde1... is uploaded to multichunks/multichunk-fde1... on the remote repository.
Note that only the delta information is uploaded — so neither the actual chunk data of the redundant chunk (with checksum 81af...) is uploaded again, nor the metadata of database version A1 (above the dotted line). Syncany is fully delta-based!
4.3. Behavioral logic (operations)
Syncany’s behavioral logic is largely grouped in the org.syncany.operations package. To keep the application architecture as simple as possible, the application logic is implemented in several Operations. Much like a function call, each of these operations can take OperationOptions as input and must return an OperationResult as output. Each of these operations run synchronously — meaning that there is very little multi-threading in the application. This keeps it simple, but obviously leaves room for performance improvements.
The most interesting operations are the ones that are mirrored by the CLI (see above in chapter 3) — namely the StatusOperation, UpOperation, LsRemoteOperation and DownOperation.
I explained the purpose of these operations (and the corresponding commands) above, so it wouldn’t make sense to explain them again in this section.
However, I’ll largely focus on the DownOperation in one of my next Syncany-posts, so you’ll get an even deeper understanding of the underlying algorithms.
5. Try it out (daily snapshots)
We’re building daily snapshots from the master branch from the latest commit (older commit builds are removed). You can check out the latest build at syncany.org/dist.
Please note: These builds are created from unstable, sometimes erroneous code. Things might change very often and newer versions might not support older repositories. Please do NOT use these builds for important files.
6. More documentation
There are tons of things you can look at about Syncany. There’s always an up-to-date list in the README file of the project or on the wiki page.
To get you started:
Posts and papers
- Blog post: Syncany explained: idea, progress, development and future (part 1) (Oct 2013)
- Master’s thesis: Minimizing remote storage usage and synchronization time using deduplication and multichunking: Syncany as an example (2011)
Screencasts
- Screencast: Developer How-to – Checkout code, compile and run two clients on Linux, using FTP plugin (14 minutes)
- Screencast: Conflict handling on Linux, using local plugin (2 minutes)
- Screencast: Setup Amazon S3 for two users, and sync two clients with Syncany (9 minutes)
Diagrams
- Diagram: Syncany application flow example
- Diagram: Chunking framework class diagram
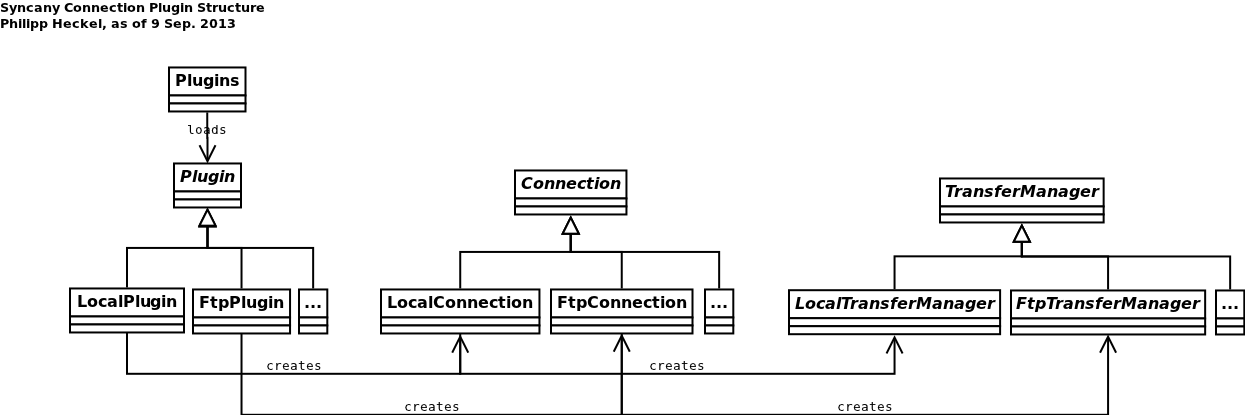
- Diagram: Storage plugins class diagram
- Diagram: Database class diagram
{kind=link}
{kind=link}
{kind=link}
{kind=link}
JavaDoc
The up-to-date JavaDoc of the master is always compiled to syncany.org/docs/javadoc.
7. Outlook on the next posts
This post is the second part of a few posts I am planning to write about Syncany. The first post was mainly about the general application, the idea and my progress over the last few years. In this post, I originally wanted to include a lot more topics, but the text grew so quickly that it didn’t make sense to put it all in here.
In the next post, I’ll write about the crypto concept of Syncany as well as about the file synchronization mechanisms.
Like always: If you have any questions, fire away in the comments section below, fork me on Github, or ask stuff on the Launchpad mailing list.
Guck dir mal TarSnap an (http://www.tarsnap.com). Könnte dich interessieren / inspirieren. Bin über die BouncyCastle Mailingliste auf deine Webseite aufmerksam geworden, und bin dann über Syncany gestolpert. Beim Lesen deiner Ziele/Probleme musste ich immer wieder an Tarsnap denken.
Viele Grüße,
Georg
Hi Georg,
for the non-Germans, here’s a rough translation: “Just look at Tarsnap (http://www.tarsnap.com). Might be interesting / inspiring. I became aware of your website through the BouncyCastle mailing list, and then I stumbled across Syncany. Reading your goals / problems I could not stop thinking of Tarsnap.”
Tarsnap certainly looks very interesting. The mission is indeed very similar to Syncany — at least the “for the truly paranoid” part. However, from what I can see it does not support multiple storage types and I’m not sure if you can use your own storage. I’ll definitely looks at it a bit more!
Best,
Philipp
PS: If you’re interested, also look at the other posts, diagrams and documentation.
PPS: I just realized that the same list is at the bottom of the blog post … In my defense: I wrote this from my smartphone… :-D
Hi,
Could you plz let me know how to install s3 plugin on windows. I am trying below command, but it is not working: “syncany plugin install s3”
It is giving error like “given command is unknown”.
Thanks
What version of Syncany are you on? Have you installed it via the installer? Is Syncany in the PATH variable? If you’ve just installed it, it might help to open a new “cmd” window. Also: You can install plugins via the GUI now. That might be easier.
Hi,
Many thanks for the reply.
I have installed syncany via the installer. Also set PATH variable. After that i have opened cmd window and run the command as “syncany plugin install s3″, but getting error like “given command is unknown”. Please let me know how to run syncany command from cmd window.
Also I would like to inform that I have installed syncany on Linux and Ubuntu server and there i have used the command “sh sy plugin install s3” and this is working fine. But in both servers i have to manually go to path like “/home/user/syncany/build/install/syncany/bin”, only then i am able to run the command. Please let me know also how to set path on Linux, Ubuntu and Windows, so that i can run syncany command from any path. I have checked syncany documents, but didn’t get any success. If you could share more examples with videos, that would be really appreciated.
Thanks
Please refer to the installation section in the user guide for all of your questions. It will answer them all: http://syncany.readthedocs.org/en/latest/installation.html