

Minimizing remote storage usage and synchronization time using deduplication and multichunking: Syncany as an example
Contents
Download as PDF: This article is a web version of my Master’s thesis. Feel free to download the original PDF version.
5. Implications of the Architecture
After discussing related research and giving an overview of the Syncany architecture, this chapter focuses on optimizing the bandwidth and storage utilization. It discusses the implications of the software architecture on the storage mechanisms and explores their trade-offs.
In particular, it examines how the concepts used within Syncany (e.g. deduplication and storage abstraction) affect the bandwidth consumption of the application and how it impacts the local computing resources.
The chapter then discusses the various existing possibilities of the algorithm design and introduces the relevant parameters. Before finally discussing different algorithm configurations and their characteristics, it briefly explains the concept of multichunks.
5.1. Implications of the Syncany Architecture
The Syncany architecture as discussed in chapter 4 has direct implications on the possible variations of the deduplication mechanisms. Among others, it affects encryption and bandwidth consumption. The following sub-sections elaborate on the strongest of these effects.
5.1.1. Encryption, Deduplication and Compression
One of Syncany’s assumptions is that the remote storage cannot be trusted. Since public cloud resources could be used as storage, this is a valid assumption. As briefly discussed in chapter 4.5.1, Syncany uses symmetric key encryption as a countermeasure. By encrypting data before uploading it, data confidentiality can be maintained.
If encryption was the only data-altering step, the data transformation process would only have to transform plaintext into ciphertext. However, since deduplication and compression mechanisms are also involved, the process is more complicated. Encryption transforms data into a pseudo-random ciphertext that changes significantly even if only a few bytes of the source data change. Even for very similar files, the corresponding encrypted documents are most likely very different. In fact, if two source files are identical, their ciphertext is different (unless the salt is identical). Considering that deduplication exploits long sequences of identical bytes, it is obvious that it does not perform well on encrypted data. Consequently, combining the two technologies is not trivial [41]. There are at least two solutions to this issue:
The first possibility is to use convergent encryption, a cryptosystem that produces identical ciphertext files from identical plaintext files [33]. Unlike other encryption mechanisms, this variant allows the use of deduplication on the ciphertext, because for a given sequence of bytes, the output is always the same. However, since the generated cipher text is the same given a specific input, it makes cryptanalysis easier and thereby reduces the overall security of the system.
The second option is to perform deduplication before the encryption [41], i.e. to break files into chunks and afterwards encrypt them individually. Since the chunk checksums are generated before the encryption, the deduplication process is not interfered with, but the resulting data is still encrypted. However, even though this is a viable option, the non-obvious problem is the overhead created by the encryption of each chunk. Encrypting a larger number of chunks needs more time than encrypting one chunk of the same size. Similarly, it creates a higher byte overhead in the ciphertext. Encrypting 1 GB with AES-128 in 1 MB blocks, for instance, only creates an overhead of 16 KB in total (16 bytes per chunk). Using 8 KB chunks for the same data, the byte overhead is 2 MB.1
Even though the overhead is not significant on its own, it must be considered in combination with other metadata such as chunk checksums or versioning information. Additionally, depending on the storage type, chunks might not be stored in raw binary format, but using inflating encoding mechanisms such as Base64.
Having that in mind, the best option to optimize disk usage is to combine the unencrypted chunks into larger chunks and then encrypt them together as if they were a single file. This reduces the data overhead and minimizes the required time. This concept is further described in section 5.1.3.
5.1.2. Bandwidth Consumption and Latency
Syncany stores chunks and metadata on the remote storage using a minimal storage interface (as described in section 4.5.4). This lightweight API allows using almost anything as storage, but at the same time creates problems with regard to deduplication, concurrency control and change notification — and thereby strongly impacts the bandwidth consumption of the application.
Unlike most file synchronizers and versioning systems, Syncany’s architecture does not include any intelligent servers, but instead only relies on a simple storage system. Unison and rsync, for instance, perform processing tasks on both participating systems. They generate file lists and checksums on both machines and exchange the results. Not only does this limit the processing time required by each of the machines, it also conserves bandwidth.
Syncany cannot rely on information created by the remote system, but instead has to download the complete file histories of all participating clients. Depending on the number of users, this can have a significant impact on the amount of data that needs to be downloaded (and processed) by each client.
With regard to change notification, the server cannot actively notify its clients of any changes on the files. Syncany must instead use alternative methods to determine if updates are available. Given the heterogeneity of the storage types, the easiest way to do this is polling, i.e. to frequently query the remote storage for changes. In comparison to push-based notifications, polling negatively affects the liveness of the updates, but more importantly potentially consumes significant bandwidth. Assuming a polling interval of ten seconds and an efficient organization of the repository on the remote storage,2 polling consumes a few dozen kilobytes per minute. If the repository is not efficiently organized, the polling bandwidth can rise up to a few hundred kilobytes per minute. Depending on the amount of users and whether traffic is costly, polling can have significant impact on the overall bandwidth and cost.
Another factor that strongly influences the required overall bandwidth consumption is the individual protocol overhead. Due to the fact that Syncany works with different storage protocols, it cannot rely on an efficient data stream, but has to consider the heterogeneous behavior of these protocols. Among others, they differ in terms of connection paradigm, encryption overhead and per-request overhead:
- Connection paradigm: Communication protocols can be divided by whether or not they need to establish a connection to the remote machine before they can communicate. While connection-oriented protocols need to do so, connectionless protocols do not. Connection-oriented protocols (such as SSH or FTP) typically have a higher one-time overhead, because a session between the two machines must be established before the actual payload can be sent. While this usually means that subsequent requests are more lightweight and have a smaller latency, it also implies a consequent connection management on both sides. Requests in connectionless protocols (such as HTTP/WebDAV or other REST-based protocols) are usually more verbose because they must often carry artificial session information. This not only negatively impacts the bandwidth, but also often the latency of connections.
Even though the Syncany storage API works with both paradigms, it requires the plugins to handle connections on their own. That is especially connection-oriented protocols must disguise the connection management and behave as if they were connectionless. - Encryption overhead: If the communication protocol is encrypted using TLS, the initial connect-operation is preceded by the transport-level TLS handshake and the actual payload is encrypted with a session key. While TLS ensures that all communication between the two machines is secure, it also adds reasonable overhead to the connection: The handshake exchanges certificates, cipher suites and keys and thereby increases the latency before the first payload can be sent. Because subsequent messages are encrypted with a symmetric key, their overhead and latency is not significant.
- Per-request overhead: The per-byte overhead of request and response headers differs greatly among the different application protocols. While distributed file system protocols such as NFS or CIFS have very lightweight headers and messages, many others are rather verbose. Especially SOAP or REST-based protocols have very descriptive headers and often require inflating encodings for binary data. If an IMAP mailbox is used as storage, for instance, payload is typically Base64 encoded and hence grows by about 30%. Another example is the overall size of a list-request and response in the FTP and WebDAV protocol: While retrieving a file list via FTP only requires an overhead of 7 bytes, WebDAV needs at least 370 bytes per request/response cycle.3
These protocol-dependent properties imply that Syncany must adapt to counteract the heterogeneity in bandwidth consumption and latency. In particular, it must try to reduce the total amount of requests in order to minimize the overall byte overhead and latency. A key factor to regulate the request count is the average chunk size: Assuming that each chunk is stored in a separate file, increasing the average chunk size reduces the per-chunk bandwidth overhead. Conversely, the more chunks must be transferred, the higher the overall overhead.
Assuming that upload-requests have a similar overhead as list requests, uploading 1 GB of data (with an average chunk size of 8 KB) would only require a total overhead of (1 GB / 8 KB) × 7 bytes = 875 KB for FTP, whereas for WebDAV, the overhead would be about 46 MB. With an upload bandwidth of 70 KB/s that would be 11 minutes for WebDAV, compared to only 12 seconds for FTP.4
5.1.3. Reducing Requests by Multichunking
Other synchronization software reduces the request count by combining many small files into a single file stream. rsync, for instance, uses only one data stream per transfer direction. Due to the fact that the software runs on both machines, it can split the stream into individual files on retrieval. Instead of having to send one request per file, it only sends two requests in total (constant time).
While this technique works if the storage host can perform intelligent tasks, it does not work with Syncany’s storage concept. Due to its abstract storage interface, uploaded data cannot be processed or transformed on the remote storage, but always stays unaltered. In particular, because files cannot be split, combining all of them into a single large file before upload is unreasonable.
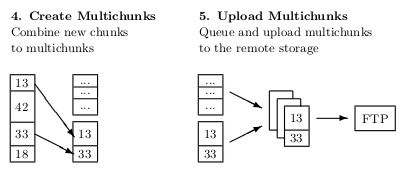 |
| Figure 5.1: The multichunk concept extends the deduplication process (cf. figure 3.1) by combining the resulting chunks in a larger container. It thereby minimizes the amount of upload and download requests. |
This thesis proposes a solution to this issue: By adding many chunks to a large container, a multichunk, it reduces the per-request overhead significantly. Instead of storing each chunk individually, many chunks are combined into a single multichunk and then uploaded to the remote storage. Due to the drastic reduction of files, the amount of requests can be reduced significantly and thereby speed up the upload (and download) of a certain file set. For the example above, combining 8 KB chunks into 512 KB multichunks reduces the WebDAV overhead to about 720 KB (10 seconds) and the FTP overhead to only 14 KB (200 ms).
However, while the multichunking concept reduces the amount of requests, it increases the amount of required metadata. Without multichunks, the index must only contain a list of chunks as well as a mapping between files and chunks. With multichunks, an additional mapping between multichunks and chunks is necessary to identify the file a chunk is stored in.
Another great disadvantage of the multichunking concept is that in order to retrieve a single chunk from the remote storage, Syncany must download the entire multichunk which contains this chunk. In a worst case scenario, even if only a single chunk is needed from a multichunk, the complete multichunk must be retrieved. In the example above, the retrieval of an 8 KB chunk would imply the download of a 512 KB chunk — producing a download overhead of 502 KB (98%).
5.2. Design Discussion
The apparent goal of the chunking algorithm is to reduce the amount of required storage space on the remote repository as well as to maximize the required upload and download bandwidth. While these goals are the primary objective, they cannot be examined in an isolated environment. Since the software will be running on an end user client, the proposed mechanisms must make sure that they do not disturb the normal execution of other applications — especially in terms of processing time and bandwidth usage. On the other hand, they must not slow down the indexing operation or negatively affect the system load.
The mechanisms developed in the scope of this thesis must not be optimized for a general purpose, but should rather be tailored to the scope and architecture of Syncany. That means that they have to consider Syncany’s unique properties such as encryption or storage abstraction.
Additionally, it is important to mention that even though the goal is to minimize disk utilization on the remote storage, this goal is not meant to be reached by the first upload, but rather within a well-defined period of time. That is the storage optimizations to be discussed do not aim on reducing the size of a single file set, but rather try to exploit the similarities between two or more versions of the same set of files. Even though they can in some cases already reduce the total file size with the first index process, the best results are to be expected for file sets with regular, but comparably small changes. Examples include the folders with office documents or e-mail archive files.
The following sections elaborate the possible variations of the algorithms and their relevant parameters. Since the efficiency of the deduplication process strongly depends on how these parameters are combined, a primary goal of the experiments below is to find the optimal configuration of these parameters with regard of the data typically found in Syncany folders.
5.2.1. Chunking Parameters
Arguably one of the most important aspects is the chunking mechanism, i.e. the method by which files are being broken into pieces to identify duplicate parts among different files. Not only can this algorithm influence the deduplication ratio, it can also have a significant impact on the indexing speed, local disk utilization and other factors.
| Chunking | Fingerprinting | Chunk Size | Chunk ID | Indexing |
| Whole File (SIS) | None (fixed only) | 2 KB | MD5 | In-Memory (Flat) |
| Fixed Offset | Adler-32 | 4 KB | SHA-1 | In-Memory (Tree) |
| Variable TTTD | PLAIN | 8 KB | … | Persistent Database |
| Variable Kruus | Rabin | 16 KB | Extreme Binning | |
| Type-Aware | 32 KB | … | ||
| … |
Table 5.1: Possible configuration parameters for chunks. Only values in bold font are considered in the experiments in chapter 6.
Many of the possible chunking options have been discussed in chapter 3.4. The most important parameters of how to break files into chunks are chunking method, fingerprinting mechanism, chunk size, chunk identity hash function as well as index structure. A selection of the possible values is depicted in table 5.1.
The average chunk size is expected to have the biggest impact on the efficiency of the deduplication process. In general, small chunks lead to better space savings than big chunks, but need more processing time and generate more metadata. Common chunk sizes in commercial deduplication systems are 2 — 64 KB.
Another major factor is the chunking method: Since it defines the general chunking algorithm, it decides whether files are broken into chunks at well-defined offsets (fixed-size), based on the file content (variable-size), file type (type aware) or not at all (SIS). For the content-based chunking methods, both the chunking method and the fingerprinting mechanism are responsible for finding the file breakpoints.
The last two parameters (chunk identity function and indexing method) have no influence on the deduplication process, but rather on the size of the metadata, the indexing speed and the processing time. Consequently, they also affect the bandwidth consumption when uploading/downloading chunks to the remote storage: The chunk identity function generates a hash over the chunk contents. Because chunks are identified with this function, it must be resistant against collisions. At the same time, its bit-length affects the amount of generated metadata. The indexing mechanism (in-memory vs. on-disk) only affects the indexing speed. For the expected amount of data to be handled by Syncany, an in-memory index is the best option, because it avoids time consuming disk lookups.
5.2.2. Multichunking Parameters
The multichunking concept, i.e. the combination of many chunks into a large file container, minimizes the overall transfer overhead by reducing the total amount of files and thereby the overall amount of upload/download requests. While the general idea is straightforward, the concept allows for some variation in the container format as well as on how the container is post-processed before storing/uploading it. Table 5.2 shows a limited set of possible parameters.
| Container | Min. Size | Compression | Encryption | Write Pause |
| None | 125 KB | None | None | None |
| ZIP | 250 KB | Gzip | AES-128 | 30 ms |
| TAR | 500 KB | Bzip2 | AES-192 | 50 ms |
| Custom | 1 MB | LZMA/7z | AES-256 | … |
| … | … | Deflate | 3DES-56 | |
| … | 3DES-112 | |||
| … |
Table 5.2: Possible multichunk configuration parameters. Only values in bold font are considered in the experiments in chapter 6.
A multichunk container can be any composite file format. It can either be an existing format such as TAR or ZIP or a custom format specifically designed for Syncany. While known file formats are more convenient in terms of development (because chunks can be simply added as file entries), they produce larger output files than a customized slimmed-down file format (particularly because they store additional metadata and chunk identifiers need to be encoded). The experiments only consider a well-defined Syncany specific format.
In order to influence the actual amount of requests, the most important parameter is the minimum size of the container file. Due to the fact that larger container files lead to fewer upload/download requests, it is generally more desirable to produce large multichunks. However, because multichunks cannot be extracted on the remote storage, downloading a single chunk always implies downloading the entire corresponding multichunk. Hence, the goal is to find a reasonable trade-off between multichunk size and the amount of unnecessarily downloaded bytes. The experiments analyze this trade-off by looking at the reconstruction overhead and bandwidth.
Apart from the minimum size parameter, the type of post-processing also influences the resulting multichunk. Before a multichunk is uploaded to the remote storage, Syncany must encrypt the data and might perform additional compression.
In order to encrypt a multichunk, any symmetric encryption mechanism can be used (cf. chapter 4.5.1). Besides the level of security they provide, the possible algorithms (such as AES or 3DES) mainly differ in terms of processing time and the amount of generated output data. While these factors affect the overall bandwidth consumption and the indexing speed, they are not relevant for optimization purposes, but rather a security trade-off the user must decide. The experiments in this thesis only use AES-128.
In contrast, the choice of the compression algorithm should not be a user decision, but can be chosen to make the resulting multichunk size minimal and the processing time acceptable. The trade-off in this case is not security, but the amount of processing resources used by the algorithm. If compression is used, writing a multichunk creates significant CPU time overhead (compared to no compression). The experiments are limited to the options no compression, Gzip and Bzip2.5
Due to the many CPU intensive processing steps of the chunking algorithm (chunking/fingerprinting, indexing, encryption, compression), the CPU usage is potentially very high and most certainly noticeable to the user. Because it is not possible to skip any of these steps, artificial pauses are the only option to lower the average CPU load. Instead of writing one multichunk after the other, the algorithm sleeps for a short time after closing the multichunk. Even though this technique helps limiting the CPU utilization, it also slows down the indexing speed. The experiments test sleep times of 0 ms (no pause) and 30 ms.
5.3. Algorithm Discussion
Given the set of configuration parameters discussed above, the chunking and indexing algorithm has a very similar structure for all the different values. In fact, it can be generalized and parameters can be passed as arguments. The result is a very simple chunking algorithm, which (a) breaks files into chunks, (b) identifies duplicates and (c) adds new chunks to the upload queue.
Listing 5.1 shows a simplified version of this generic algorithm (disregarding any encryption, compression or multichunking mechanisms):
|
1 2 3 4 5 6 7 8 9 10 11 12 |
void index(files, config): for each file in files do: chunks = config.chunker.create_chunks(file) while chunks.has_next() do: chunk = chunks.next() if index.exists(chunk.checksum): // existing chunk existing_chunk = index.get(chunk.checksum) ... else: // new chunk index.add(chunk) upload_queue.add(chunk) ... |
Listing 5.1: Generic chunking algorithm (pseudo code).
The algorithm’s input parameters are the files to be indexed as well as the chunking parameters (config). Any of the chunking parameters (such as chunking method or chunk size) are comprised within the config.chunker object. The algorithm breaks each file into individual chunks (line 3) and checks if each of them already exists in the index. If it does (line 6), the existing chunk can be used. If it does not (line 9), the chunk is added to the index and queued for uploading.
Depending on the desired chunking options, a corresponding chunker has to be created. If, for instance, fixed-size chunking with a maximum chunk size of 8 KB and MD5 as identity function shall be used, chunking and indexing a given set of files can be done as shown in listing 5.2. In order to use other chunking mechanisms and parameters, the configuration needs to be adjusted with the according parameters.
|
1 2 |
config = { chunker: new fixed_size_chunker(8000, "MD5") } index(files, config) |
Listing 5.2: Example algorithm call using fixed-size 8 KB chunks with a MD5 chunk identity function.
While this algorithm describes the basic deduplication mechanisms, it does not encompass the concepts of multichunks, encryption or compression (cf. table 5.2). To allow the use of these concepts, it must be extended accordingly:
- Multichunks: To allow multiple chunks to be stored inside a single container (or multichunk), the algorithm must keep track of the currently opened multichunk and close it if the desired minimum multichunk size is reached.
- Transformation: Before writing the multichunk to the local disk (or uploading it), encryption and compression must be performed. Because both of them alter the original data stream, they can be classified as transformation.
- Write pause: After closing a multichunk, a short sleep time might be desired to artificially slow down the chunking process (and thereby limit the CPU usage).
The new multichunking algorithm in listing 5.3 encompasses all of these changes:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
void index_multi(files, config): for each file in files do: chunks = config.chunker.create_chunks(file) while chunks.has_next() do: chunk = chunks.next() if index.exists(chunk.checksum): existing_chunk = index.get(chunk.checksum) ... else: if multichunk != null and multichunk.is_full(): // close multi multichunk.close() upload_queue.add(multichunk) multichunk = null if multichunk == null: // open multi multichunk = config.multichunker.create(config.transformerchain) index.add(chunk, multichunk) multichunk.write(chunk) ... if multichunk != null: // close last multi multichunk.close() upload_queue.add(multichunk) |
Listing 5.3: Generic multichunking algorithm (pseudo code).
While this algorithm behaves identically in case the chunk already exists in the index, it has a different behavior for new chunks (highlighted in dark gray, lines 10-24): Instead of queuing each individual chunk for upload, this algorithm adds it to the currently opened multichunk (line 19). If the multichunk is full, i.e. the minimum multichunk size is reached, it is queued for upload (lines 10-13).
After closing a multichunk, the algorithm creates a new one using the configuration parameters defined by the config argument (lines 15-16). This particularly comprises instantiations of a multichunker (such as a TAR or ZIP based multichunker), as well as a transformerchain (e.g. a combination of Gzip and a AES cipher).
Continuing the example from listing 5.2, the following configuration additionally uses 512 KB TAR multichunks, a 15 ms write pause, Gzip compression and AES encryption (figure 5.4):
|
1 2 3 4 5 6 7 |
config = { chunker: new fixed_size_chunker(8000, "MD5"), multichunker: new tar_multichunker(512*1000, 15), transformerchain: new gzip_compressor(new cipher_encrypter(...)) } index_multi(files, config) |
Listing 5.4: Example algorithm call using fixed-size 8 KB chunks, a MD5 chunk identity function, 512 KB TAR multichunks, a 15 ms write pause and Gzip compression.
This generic algorithm allows for a very simple comparison of many different chunking and multichunking configurations. The experiments in this thesis use the algorithm and a well-defined set of configuration parameters to test their efficiency and to identify the best configuration for Syncany.
- 1 This has been tested and verified by the author.
- 2 The current version of Syncany does not always efficiently organize files on the remote storage. Instead, it stores chunks and metadata without any hierarchy in a flat list of files.
- 3 Tested by the author. The calculation does neither include the overhead generated by the underlying protocols (TCP/IP), nor the per-entry bytes. It only includes the fixed amount of header and payload bytes. For FTP, this is simply the command LIST -a. For WebDAV, this includes the PROPFIND request and a 207 Multi-Status response.
- 4 Since Syncany is an end-user application, upload bandwidth in this example is assumed to be typical DSL upload speed.
- 5 Due to the high number of other parameters and the resulting number of possible configurations, only very few options can be compared within this thesis.
Hi,
I would love to see a ebook version of your thesis (epub or mobi). Would that be possible ?
thanks
@JP: Is there a simple way to compile it from LaTeX format? If it is, I can definitely make one for you. Just let me know :-)
Hi Philipp:
Good Morning. Possible to receive pdf version of your thesis.
cheers
Madhavan