

Minimizing remote storage usage and synchronization time using deduplication and multichunking: Syncany as an example
Contents
Download as PDF: This article is a web version of my Master’s thesis. Feel free to download the original PDF version.
4. Syncany
This chapter introduces the file synchronization software Syncany. It describes the motivation behind the software, its design goals as well as its architecture. The main purpose of this chapter is to create a basic understanding of the system structure and process flows. This understanding is of particular importance to comprehend the implications that the design choices and final software architecture have on the algorithms proposed in chapter 5.
4.1. Motivation
The motivation behind Syncany arose from the increasing rise of the cloud computing paradigm and the associated desire to store and share files in the cloud. Companies like Dropbox or Jungle Disk have shown that there is a need for easy file synchronization among different workstations. While many applications provide synchronization functionalities as part of their feature set, most of them are tied to a specific storage protocol, lack security features or are not easy enough to use for end-users.
Syncany overcomes these issues by adding an extra layer of security and providing an abstract storage interface to the architecture. To ensure confidentiality, it encrypts data locally before uploading it to the remote storage. The abstract storage interface allows Syncany to use any kind of storage. Users can decide whether to use private storage such as a NAS in the local area network or public cloud resources such as Amazon S3. The goal of Syncany is to offer the same features as other solutions, but add encryption and a more flexible storage interface.
While there are a many applications with similar functionality, there are to the best of the author’s knowledge no tools that satisfy all of these requirements and are at the same time open to modifications and adaption by other developers. Syncany attempts to fill this gap by providing an easy-to-use end-user oriented open source file synchronization application.
Although this thesis strongly relies on Syncany, it does not focus on the application itself, but rather on optimizing its chunking algorithms and resource usage. The thesis uses Syncany as test bed for the deduplication experiments and aims to optimize storage usage and bandwidth consumption in a real-world scenario. For these experiments, Syncany provides an optimal environment and offers the potential for field tests in future research.
Due to these aspects, Syncany is considered an essential part of this thesis.
4.2. Characteristics
The main goal of Syncany can be fulfilled in various ways. To reduce the ambiguity, this section describes the required functionalities in greater detail. Many of these requirements can also be found in related software such as distributed file systems or versioning software [13,23]:
- File synchronization: The key purpose of the system is to allow users to backup and synchronize certain folders of their workstation to any kind of remote storage. This particularly includes linking different computers with the remote storage to keep files and folders in sync on different machines. The amount of both transferred and remotely stored data should be reduced to a minimum.
- Versioning: The system must keep track of changes on files and folders. It must be able to store multiple versions of the same file in order to allow users to restore older versions from the remote repository at a later point in time.
- Storage independence: Instead of creating software that works on top of a specific storage type, the user must be allowed to decide which storage type and provider to use. Users must be able to use their own storage as well as public cloud resources. Examples for possible storage types include FTP, IMAP or Amazon S3.
- Security: Since the storage is potentially operated by untrustworthy providers, security is a critical requirement. In particular, confidentiality and data integrity must be ensured by the system. Since availability depends on the storage type (and hence on the storage provider), it is not a core requirement of the system.
- Openness: The system must be designed to be open for extensions and contributions by third parties. To ensure maximal benefits for users, it must be possible to use the software on different platforms and free of charge.
- Ease-of-use: Rather than providing an extensive set of features, the goal of the system must be to provide an easy-to-use interface for end-users. While it should not stand in the way of new functionalities, ease-of-use is a crucial element for the acceptance of the software.
- Multi-client support: Unlike other synchronization software such as rsync or Unison, the system architecture shall support the synchronization among an arbitrary number of clients.
While the list of requirements is rather short, they have significant impact on the architecture of the system and the design choices. In particular, the requirement of file synchronization can be achieved in many different ways as shown in chapter 2. The following sections discuss the choices made as well as the final architecture of the system.
4.3. Design Choices
Obviously, the final architecture of Syncany fulfills the above defined requirements. However, since there are certainly multiple ways of achieving the defined goals, a few fundamental design choices have been made. The following list shows the major decisions and explains their rationale:
- Lightweight user-interface: The Syncany user-interface is deliberately reduced to a minimum. Synchronization is done in the background and only indicated by emblems in the operating system’s file browser.
- Programming language: The majority of Syncany is written using the Java programming language. Main reasons for this decision are the platform independence, the maturity of the language as well as the large amount of available open-source libraries.
- No-server architecture: With regard to the ease of use requirement, Syncany only consists of a client. It requires no servers and thereby simplifies the usage and configuration for end-users significantly. The only servers involved in the system are the storage servers which can be either self-operated or operated by storage providers such as Amazon or Google.
- Minimal storage API: The above described storage independence can only work if Syncany is able to address storage in the very generic way. The Syncany storage API hence defines a generic storage interface and can use many different plugins.
- Implicit commits/rollbacks: Unlike most versioning software, Syncany never assumes that the local copy of files is in a final committed state. Each client keeps its own history and frequently compares it to the other clients’ histories. This approach is particularly useful, because there is no central instance for coordination or locking. Details on this concept are explained in section 4.5.3.
- Trace-based synchronization: Syncany uses a trace-based synchronization method to detect and reconcile changes among the clients. Rather than comparing only the final states of the client file trees, it compares their entire histories (trace log) [56,53]. While this method certainly is more bandwidth and storage intensive, it is required to trace changes and allow restoring arbitrary file revisions.
4.4. Assumptions
The Syncany architecture is strongly tied to a small set of assumptions all of which must hold for the system to work properly. The following list briefly explains the most important ones:
- Untrustworthy storage: The remote storage Syncany uses as its repository is not assumed to be trustworthy. Similar to other systems [13], Syncany trusts the server to store data properly, but does not assume that the data cannot be accessed by others. Although data stored remotely can be altered or deleted, Syncany makes sure that third parties cannot access the plain text data and that changes in the data are detected.
- Trusted client machine: Unlike the storage servers, client machines are assumed to be trusted. Data is stored in plain text and no encryption is applied locally.
- Limited amount of data: While Syncany can handle large amounts of data in a single repository, it assumes that the client application is used by end-users. It hence does not manage amounts over a few dozen gigabytes.
- Collision resistance: Cryptographic hash functions such as the ones used in chunking algorithms are assumed to be collision resistant, i.e. hashes of different input strings are assumed to produce different outputs.
4.5. Architecture
Syncany is split into several components with different responsibilities. Each component encapsulates a particular functionality and interacts with other components in the application.
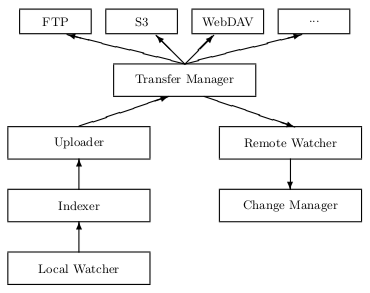 |
| Figure 4.1: Simplified Syncany architecture. When the local watcher detects changes in the watched folders, it passes the events to the indexer which then breaks the files into chunks. New chunks are uploaded by the uploader using a transfer manager. The remote watcher detects and downloads changes from the remote storage and passes them to the change manager which then applies these changes locally. |
The general architecture is straightforward: On the one hand, Syncany must watch the local file system for changes and upload altered files to the remote storage. On the other hand, it must handle changes made by other clients or workstations and apply them on the local machine. The Syncany architecture can be logically split according to these two process flows. The two processes are indicated on the left and right side of figure 4.1:
Local changes: For each user-defined Syncany folder on the local file system, the application registers a watch in the LocalWatcher. This watcher receives file system events from the operating system (OS): If a user creates, updates, moves or deletes a file in one of the watched folders, an event is triggered by the OS. This event is pre-processed by the watcher and then handed over to the Indexer. The indexer analyzes each file, splits it into chunks and adds metadata to the local database. If parts of the file have changed, it passes the according chunks to the Uploader which uses a TransferManager to upload them to the remote storage.
Remote changes: If other clients change a file on the remote storage, the local client must learn about these changes and apply them locally. Due to the heterogeneity of the repositories, the remote storage cannot actively notify clients that files have been updated. Instead, clients use the RemoteWatcher to poll for changes regularly. If new file entries or updates to existing entries have been found, the ChangeManager combines the clients’ file histories to one single history and identifies conflicts. It then applies these changes to the local file system.
The following sections give an overview over the most important concepts within Syncany.
4.5.1. Encryption
One of the core requirements of Syncany is the ability to use virtually any online storage without having to trust the owner of that storage. That is Syncany must ensure that data confidentiality is protected by any means. While this requirement can be easily achieved using modern encryption methods, the solution must consider other requirements and design goals.
There are a variety of ways to ensure that the desired security properties are protected. They use different cryptographic primitives to transform the plaintext files into cipher text before uploading them to the remote storage. Depending on the used method, it is possible to implement cryptographic access control [26,13], i.e. to cryptographically ensure that certain files can be read or written only with the respective access rights:
- Single symmetric key: The easiest method is to use a single symmetric key, derived from a user password, to encrypt chunks and metadata. Users with the password can decrypt all the data in the repository with only one key. While this is a very convenient possibility to achieve confidentiality, it is vulnerable to cryptanalysis if enough chunks are analyzed.
- Salted symmetric key: Similar to the single symmetric key method, this method uses one password to encrypt chunks and metadata, but salts the key with the checksum of each individual chunk (or any other value known to the client). This makes attacks on the key more difficult because it effectively encrypts each chunk with a different key. Users still have to remember only one password, but the system can create a key for each chunk. All users owning the password would hence be able to read/write all files.
- Random symmetric keys: Instead of creating a key from a single password, this method creates a random key for each chunk and stores the value in the metadata. The client must look up the key in the metadata to encrypt/decrypt the respective chunks. Due to the additional random key, this method requires significant per-chunk storage overhead.
- Asymmetric keys: The symmetric key methods grant all users with a valid key full access to all files and folders. Asymmetric cryptography, however, uses different keys to encrypt/decrypt data and can be used to implement multi-user support using cryptographic access control. Each client has its own key pair and encrypts files with a random symmetric key. This symmetric key is then encrypted with the public key of all clients with full access. If a client wants to decrypt a file, it has to first decrypt the symmetric chunk key with its own private key and can then decrypt the chunk.
The current architecture of Syncany uses a salted symmetric key based on the user password. There is no multi-user support and clients with the password have full read/write access to the repository. While this concept does not allow limiting access to a subset of users, it minimizes the computation required by the client and reduces complexity. The concept of a password is much easier to understand for end users and thereby matches the ease-of-use principle more than the asymmetric variant.
4.5.2. Versioning Concept
One of the requirements of Syncany is to allow versioning of files — in particular to allow restoring older file versions from the remote storage. Since the files and folders in the repository need to be encrypted and multiple storage types must be supported, none of the currently available version control systems are suitable. Syncany can hence not use any existing versioning mechanisms, but has to provide its own versioning system.
In contrast to traditional versioning software, Syncany must not support the full breadth of features and commands, but instead only focuses on what is required for its specific use case. In particular, Syncany’s versioning mechanism does not need to support the concepts of tags, branches or file merging. Instead, it rather focuses on tracking the version of a file as well as detecting and resolving conflicts.
Deduplication vs. Delta Compression: As indicated in chapter 2.2, most revision control software use snapshots and delta compression [58] to record changes between file revisions. This works very well for text files and satisfactory for binary files, but has significant disadvantages. When a file is changed locally and committed to a repository, the VCS must calculate the difference between the two revisions. To do that, it needs both versions of the file on the same machine. That is the VCS must (1) either upload the local file to the remote repository and then compare it with the old version or (2) keep a second copy of the old file on the local file system.
In the first case, it must transfer the entire new file even if only a single byte has changed. This potentially consumes enormous amounts of bandwidth and thereby defeats the purpose of the delta compression concept. An example that uses this variant is CVS.
In the latter case, the VCS effectively has to store each file twice on the local machine: the working copy as well as the complete history of the file. In the worst case, this requires up to double the amount of disk space. Examples that behave like this are Subversion and Bazaar.1 Both variants are acceptable if the upload bandwidth is sufficient and local disk space is not an issue. If, however, large files are to be stored in the repository, deduplication is more suitable than delta compression based VCS. Instead of having to compare the old version of the file with the new version, it creates chunks by using the locally available file and only uploads new chunks to the remote repository. That is it does not need an old version to compare, but only requires the newest file as well as a list of existing chunks. This method avoids having to upload the whole file and eliminates the need to store the entire change history locally.
Taking the requirement of client-side encryption into consideration, this disadvantage of delta compression becomes even more evident. In an encrypted VCS, the binary diffs stored in its repository have to be encrypted as well. That is if a file gets updated locally, the diff operation not only requires the version history to be read, but also implies several decryption operations prior to it. Since this has to be done for all altered files and every commit operation, the impact on performance would be significant.
As a consequence of the issues listed above, Syncany’s versioning system uses deduplication rather than delta compression: It breaks new or updated files into chunks and stores their identifiers in its local database. Each file consists of a set of chunks in a specific order. When small parts of a file change, the majority of the chunks are still identical. Syncany only has to upload the chunks that overlap with the updated parts of the file. The details of the deduplication algorithms are discussed in chapter 5.
Optimistic vs. Pessimistic Versioning: As soon as more than one person works with the same repository, there is a good chance that they accidentally update the same file in their local working copies. Once the clients commit their changes, the system has to deal with different versions of the same file. There are two commonly known solutions to handle this situation. The system either (1) locks the remote file while it is being written and thereby avoids conflicts in the repository or (2) it allows all clients to write the new file and resolves the issues at some later stage.
The first case is known as lock-modify-unlock in revision control or pessimistic replication in distributed systems [1,53,55]. In this model, the system locks the remote file while one client writes its changes and releases the lock once the write operation is complete. That is the repository ensures that only one client can make changes to a file at a time. This model pessimistically assumes that concurrent updates and conflicts happen regularly. While it avoids multiple versions of the same file in the repository, it relies on synchronous calls and blocks other clients during updates.
The latter case is known as copy-modify-merge in revision control or optimistic replication in distributed systems [1,77,53]. Instead of locking the repository, this model assumes that conflicts will occur only rarely and hence explicitly allows concurrent write access to the repository by different clients. The repository temporarily stores all file versions and later resolves problems by merging the changes into the working copies of the clients. This model has significant advantages over the pessimistic approach. Optimistic algorithms offer a greater availability of the system because they never have to lock files of file sets. Users work independent from each other since they do not have to rely on other users to release the lock. Instead, they commit their changes and get a quick response from the system. In addition to the improved usability and response time, optimistic systems have a higher scalability than pessimistic systems, because operations are asynchronous. This allows a large number of users/replicas to access the same system concurrently [53,77].
Syncany is based on the copy-modify-merge paradigm: In addition to the above mentioned advantages, an optimistic approach matches the purpose of the software better than a pessimistic one. Due to its asynchronous nature, it allows a more responsive user experience and can deal with variable client connectivity. Unlike most versioning software, Syncany never assumes that the local copy of files is in a final committed state. Each client keeps its own history and frequently compares it to the other clients’ histories. This approach is particularly useful because there is no central instance for coordination or locking. Details on this concept are explained in the next section.
4.5.3. Synchronization
The synchronization algorithm is one of Syncany’s core elements. Its responsibility is to detect file changes among participating workstations and to bring them to the same state. This particularly includes what is known by most file synchronizers as update detection and reconciliation [57,51,52,53,54].
Update detection is the process of discovering where updates have been made to the separate replicas since the last point of synchronization [57]. In state-based synchronizers [50] such as Unison or rsync, this is done by comparing the file lists of all replicas. The result is a global file list created by merging the individual lists into one. In trace-based synchronizers, update detection is based on the trace log of the replicas. Instead of a global file list, they generate a global file history based on the individual client histories. It typically compares histories and detects new file versions. Update detection must additionally detect conflicting updates and determine the winner of a conflict.
Once the global file list/history has been created, it must be applied to the local workstation. This is done in the reconciliation phase, which usually downloads new files, deletes old files and moves renamed files.
Due to Syncany’s versioning requirements, it detects updates via trace logs (file histories) of the individual clients. Histories of the participating clients are analyzed and compared to each other based on file identifiers, file versions, checksums and local timestamps. Syncany follows the optimistic replication approach. Clients populate their updates to the repository under the assumption that conflicts do not happen regularly. If a conflict occurs, each individual client detects it based on the trace log and determines a winner. The winning version of a file is restored from the repository and the local conflicting version is populated to the repository under a different name.
4.5.4. Storage Abstraction and Plugins
Unlike related software such as distributed file systems or versioning software, Syncany does not rely on a single type of storage, but rather defines a minimal storage interface, which makes it possible to support very heterogeneous storage types. Each supported storage is encapsulated in a plugin and must implement the generic methods upload, download, list and delete. This is a well-known approach for storage abstraction [6,16].
Each of these plugins can be used by Syncany in a very homogeneous way and without having to individually handle the different behavior of the storage types. The storage API mainly defines the exact behavior of these methods and thereby ensures that the plugins behave identically, even if they operate on entirely different protocols. Among others, the API defines the following behavior:
- All operations must be synchronous.
- All operations must automatically connect or reconnect (if necessary).
- All operations must either return a valid result or throw an exception.
- File entries returned by the list-operation must belong to the repository and match a certain file format.
- The repository must always be in a consistent state.
The main advantage of this approach is obvious: Due to the fact that plugins must only implement a very small set of generic operations, almost anything can be used as storage. This is not limited to typical storage protocols such as FTP or WebDAV, but can be extended to rather unusual protocols such as IMAP or even POP3/SMTP.
Even though this is a great advantage, the list of incompatibilities among the different protocols is long: Traditional storage protocols such as NFS or WebDAV, for instance, support multiple users and can define read/write support for different folders depending on the user. IMAP, however, has no possibility to limit access to certain folders. Similarly, CIFS supports other file permissions than NFS and FTP behaves differently on transfer failures than Amazon S3.
Even though the minimal storage interface solves these issues, it also strongly limits the potential functionalities of the remote storage server and thereby also of the application — especially in terms of supported file size, authentication and multi-user support. The storage plugins must be able to deal with these differences and behave identically independent of the underlying protocol.
>> Next chapter: Implications of the Architecture
- 1 These results have been acquired by monitoring local and remote disk usage as well as bandwidth in the following command sequence: (1) Commit a large binary file to the VCS, (2) append a single byte to the file, (3) commit again.
Hi,
I would love to see a ebook version of your thesis (epub or mobi). Would that be possible ?
thanks
@JP: Is there a simple way to compile it from LaTeX format? If it is, I can definitely make one for you. Just let me know :-)
Hi Philipp:
Good Morning. Possible to receive pdf version of your thesis.
cheers
Madhavan