
Programming
Deduplicating NTFS file systems (fsdup)
At my work, we store hundreds of thousands of block-level backups for our customers. Since our customer base is mostly Windows focused, most of these backups are copies of NTFS file systems. As of today, we’re not performing any data deduplication on these backups, which is pretty crazy considering that how well you’d think a Windows OS will probably dedup.
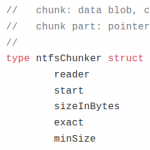
So I started on a journey to attempt to dedup NTFS. This blog post briefly describes my journey and thoughts, but also introduces a tool called fsdup I developed as part of a 3 week proof-of-concept. Please note that while the tool works, it’s highly experimental and should not be used in production!

Recent Comments