

Syncany explained: idea, progress, development and future (part 1)
Many many moons ago, I started Syncany, a small open source file synchronization project that allows users to backup and share certain folders of their workstations using any kind of storage, e.g. FTP, Amazon S3 or Google Storage.
At the time of the initial annoucement of the project (May 2011), there was a big hype around it. I received many e-mails and lots of support from people around the world. People were excited because the features Syncany offers are great: File synchronization à la Dropbox, paired with storage flexibility (use-your-own), client-side encryption (sorry about that, NSA!), and intelligent versioning.
At the time, I didn’t actually release a runnable version of Syncany. The sole purpose of the announcement (on WebUpd8 and on the Ubuntu Podcast) was to get developers excited about the project in order to get help for the last steps of creating a somewhat stable release. Unfortunately, I was further away from this “stable release” than I could have imagined.
In this blog post, I’d like to recap the idea behind Syncany, what went wrong with the development, and how I brought the project back on track (or so I believe). I’ll also talk about what I plan to do with Syncany and how people can help (if they still want).
Content
Update (28 Oct 2013): I uploaded a short screencast that shows the current code base of Syncany. It’s not much, but I think it captures very well how it works so far. The code running in the video is newer than the one in this post, but the basic idea and principles are of course the same.
Update (14 Feb 2014): I finally got around to writing the follow-up blog post to this one (part 2). Check out Deep into the code of Syncany – command line client, application flow and data model (part 2).
1. Recap of the Syncany idea
As I briefly mentioned in the introduction, the original idea behind Syncany was pretty simple: make a file synchronization software that allows you to easily exchange files with friends — but avoid being bound to a central provider, or any kind of active central system for that matter. Syncany was (and still is) supposed to be as easy to use as software like Dropbox, but have the advantage of using any kind of storage you can imagine. So, instead of having an active central component with its own proprietary protocol, Syncany was supposed to work with regular “dumb” storage like FTP, Samba, SFTP, Amazon S3, and so on. That was a very ambitious goal and it still makes things a bit more complex than it would be with a central intelligent instance.
Up to this point, the feature set sounds really nice, but it still didn’t quite cut it for me: instead of just synchronizing the current state of a folder, I wanted to add versioning capabilities, so that one could restore older versions of a file or use Syncany as backup tool with incremental backups. If you’re familiar with version control systems like SVN or Git, that’s pretty much what I wanted for Syncany. So in the end, one could either use Syncany to share a common folder with a friend and occasionally restore a file, or one could use it to backup his or her files to “the cloud” (I still don’t like saying “the cloud”, still sounds like a buzz word to me). To realize the versioning capabilities and save remote disk space at the same time, I decided to use a technique called data deduplication. Deduplication is widely used in enterprise-size backup solutions to save disk space, but it is quite uncommon for desktop applications. In a nutshell, deduplication breaks files into many data chunks (each about 8-32 KB in size) and keeps track of which chunks make up the contents of a file. Each chunk is only stored once on the remote storage, even if it appears hundreds of times on the local disk — thus saving ridiculous amounts of megabytes or even gigabytes. And remember, if you’re using Amazon S3 or any other paid storage, gigabytes equal monthly payments.
The problem with having so many storage options is that when you use a commercial storage provider like Amazon S3 or Google Storage, you never know who’s going to look at your data, or if your data is going to end up on a flash drive of an overly interested employee. Having these concerns about the long-term confidentiality of cloud storage and the providers’ trustworthiness, it was pretty obvious that files needed to be encrypted before they were uploaded. This, of course, did not make things any easier!
When you add all these features to the “pretty simple” idea from above, you suddenly get something that sounds a little less simple: Syncany became a client-side encrypted, deduplicated, storage-abstracted, multi-client file synchronization software with versioning capabilities. Pretty long and fancy-sounding phrase — now just imagine what it means to actually combine these technologies into one piece of working software?
Recaping the list of requirements so far, Syncany would have the following features:
- File synchronzation between multiple clients
- Storage abstraction, i.e. use-your-own storage
- Client-side encryption of data
- Minimal remote storage usage thru deduplication
- File versioning
Even though this already sounds pretty great, my list of requirements for the initial version of Syncany didn’t stop here. I really wanted to make it easy-to-use for everybody — which meant that a simple command line tool wasn’t enough! To make it usable by the average user, a little bit of Klickibunti was necessary — so basically a graphical user interface.
In my mind, a user interface for Syncany must consist of two things: First, a user must be able to set up a repository using an easy-to-use wizard. Ideally, he or she does not have to manually edit configuration files or do other complicated things to create a new repository or connect to an existing one. Instead, I believe that a guided step-by-step is the way to go.
Second, the user must be informed about the current state of the file synchronization — meaning that there must be an integration in the file manager, e.g. using green/blue/red indicator icons next to the files and a tray icon showing the overall progress. I already developed something like this back in May 2011. There are a few screenshots here to illustrate what I just described:
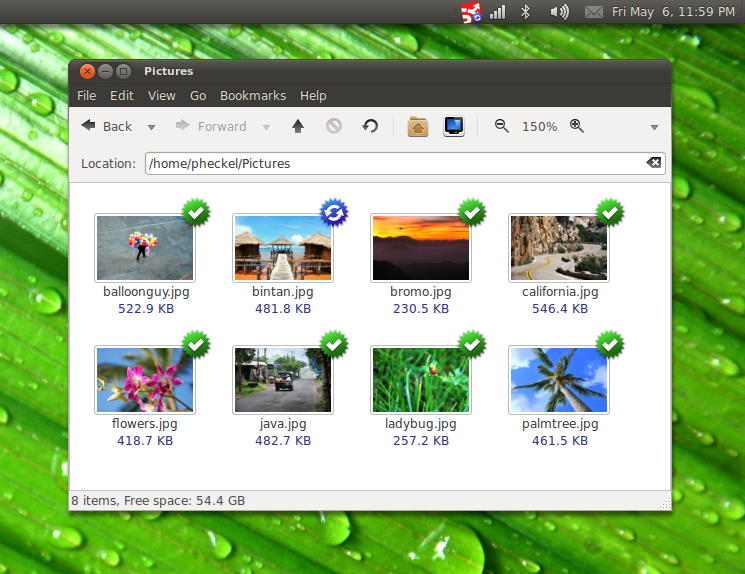
Adding up these features, I ended up with an additional three major things to do:
- Step-by-step repository setup wizard
- Platform-specific file manager integration (for Windows/Mac/Linux)
- File system watching to react on changes
Even in the first iteration of Syncany, I wanted to fit all these features into the software. And let’s be honest: You don’t have to be a genius to see that these are a lot of big time requirements. Putting all that together meant combining many more or less complex ideas.
As you might have guessed, I think that’s where it all went a little wrong.
2. What went wrong
Too many features, too many almost-working things: When I started Syncany, I wanted it all. I started to work on everything and I didn’t quite realize how complex it is going to be: synchronization, deduplication, encryption, decentralization, etc.
Simply look at the screenshots above — Syncany looks like it’s already working perfectly: There’s a step-by-step wizard user interface, Nautilus file manager integration, and files are synchronizing between clients. It’s not a fake. It worked. It still does, the trunk on Launchpad (from 2011, old!) still represents the code that you see in the screenshots.
You’re probably asking yourself what the problem with this code was (and still is). The answer to that question is really simple: The application architecture.
In short, the application had fundamental flaws in many of its central functionalities — including core components such as the file synchronization mechanism and the database structure. Here are a few examples:
- The metadata that the clients exchange was based on full CSV files (no deltas!) — meaning that the clients’ databases were basically exchanged in full whenever a tiny thing was changed. Imagine you rename a file in your Syncany folder. Syncany would add that ‘renamed’ file version to its local database and upload this database to the remote storage. If your database at that time was already couple of minutes/hours/days old, a few megabytes had to be uploaded. So instead of uploaded a delta (‘renamed version of file X’), the full database file would be uploaded.
- The file synchronization algorithm was initially based on a very straightforward idea: simply do exactly the same on each client. So if one client changes a file, this change will be recorded, transferred to the other clients, and applied on their machines. Sounds okay? Here’s the problem: If client A creates a file and changes it twice, client B has to download each version of the file and apply all updates locally (create file, change file, change file).
Instead, the sync algorithm could simply apply the last version of the file (and ignore all of the intermediates). In the newsync branch, I tried to overcome this issue by comparing the local version of the file to the target version. This is a good idea, but I failed to implement it correctly — I believe due to a lack of database structure and type clarity. - While there were many packages with distinct responsibilities, there was no real separation of concerns. Packages heavily depended on each other and were not testable individually. In fact, there were no real tests at all, making it virtually impossible to get it to a stable point. Tests consisted of the ‘classic’ trial-and-error approach.
Those are just three examples, but there are many more. In order to not make the same mistakes again, I tried to write them down in the following list. I already mentioned some of them:
- Too many features, too many almost-working things
- No working central core to build around
- No modulization, impossible to test
- Too early announcement, many people wanting to help, but I had no idea how to coordinate them
- Too early mavenization, made development harder
- No easy setup, no developer instructions
3. Current development
So where does this leave the application? What’s going to happen to Syncany in the future? Is it dead? Or will there be a release in the near future? Those are the kind of questions I receive every day — from people that are interested in the project, people that want to help out, and people that are sick of all the NSA-stories.
And those are valid questions! Heck, if I were a user (and I will be!), I’d want to know whether Syncany is just an ongoing experiment of a single person, or if it is actually going somewhere. You deserve to know. Here are some answers!
First of all: Syncany is not dead, it is very much alive and I am actively working on it every single day — on the train to work, after work and on the weekends with my friend and colleague Steffen Dangmann.
3.1. Refactoring and throwing things out
In the spirit of not making the same mistakes, we’ve done lots of work on the application architecture. We first threw out all of the non-core code — meaning file system watcher, graphical user interface, nautilus file manager extension, multi-threading, and so on — reducing the code base from about 20k lines of code and 400 lines of test code to only 8k lines of code, 122 tests in almost 6k lines of test-code, with a code coverage of about 70%.
After that, we evaluated the rest of the existing code and determined the usable parts of it — basically leaving only the chunking framework, i.e. the deduplication algorithms, and the storage/connection plugins. The rest of the code was really useful as an orientation, but most of it had to be (re-)written. In particular, that meant creating a delta-based database/metadata concept, a sensible synchronization algorithm to resolve conflicts and disk updates, and a modulized application structure (sync up, sync down, status, …).
In a nutshell, we ended up with the following core elements of the application:
- The chunking framework offers functionality to apply different deduplication mechanisms. It breaks files into chunks, combines them into multichunks (containers), and transforms these multichunks before upload (compress, encrypt).
- The database represents the internal state of a repository. It connects chunks and multichunks with the actual files and their versions. The database is used both locally to store the local state as well as to exchange the deltas with other clients.
- In order to store the delta-databases and the transformed multichunks, the connection package offers an API to create storage plugins. A plugin must offer four methods to work with Syncany: upload, download, list and delete. We added three plugins by default: local directory, FTP folder and Amazon S3 bucket.
- For the actual behavioral logic of the application, the operations package offers a set of commands that can be combined to create other commands. Central examples include ‘sync up’ (index local changes and upload), and ‘sync down’ (list remote changes, download and apply locally).
- Other not-so-central parts include the config package and the command line interface. The config package represents a repository and user config, including encryption settings, machine name and storage plugin configuration. The command line interface represents the current command line-based Syncany client syncany (or sy for short). Commands can be called like this: sy up, sy down or sy status.
This is just a short overview, of course, but I’ll be detailing this in another post. So if you’re interested in more details about the inner workings of Syncany, please check out the second of this post as soon as it’s available. I’ll link to it here once I’ve finished writing it.
3.2. Back on track!
Having heard all these fascinating aspects of Syncany, I hope you got the main message: Syncany is back on track! We learned from our mistakes and scaled down to the essential parts. We’re taking smaller steps, and each step is tested with a corresponding test scenario.
As of now, there is a central core with what currently feels very much like a version control system. As I mentioned above, there is currently no real daemon functionality, no file system watching, no GUI and no file manager integration. These are the things that will follow at a later stage, and/or can be heavily supported by the community.
3.3. Where to find the code and project
We very recently moved the code from Launchpad to Github, because the Bazaar client for Windows is really broken — and development should be easy on all of the major operating systems. There is of course still much stuff on Launchpad, but the new master/trunk is on the Github!
The project homepage hasn’t changed in two years (except for news updates), but it’s still there, with all the screenshots and a description of the core idea.
3.4. Trying out what we’ve got so far
So are you already excited? I sure am! If you’d like to try out what we’ve got so far, you can check out the current code, compile/install it yourself (simply run ant, sudo ant fakeinstall, and then syncany) and test it in the sandbox. There is a small howto in the README file.
In short, run the following commands. The main focus is Linux and Windows right now, but it should also run on Mac OS:
|
1 2 3 4 5 6 |
sudo apt-get install git ant openjdk-7-jdk git clone https://github.com/binwiederhier/syncany SyncanyCore cd SyncanyCore git checkout e3d11300b3 ant sudo ant fakeinstall |
The ‘fakeinstall’ target creates symlinks in /usr/local/bin, so that you can run syncany or sy directly from the command line.
3.5. A quick example
This tiny example uses the ‘real’ syncany command line tool. I’ll create two Syncany folders on two different users (Alice and Bob) and use an FTP folder as repository.
|
1 2 3 |
alice@wonderland:~/$ mkdir Syncany alice@wonderland:~/$ cd Syncany alice@wonderland:~/Syncany$ sy init -i |
The sy init -i command walks you through an interactive setup to create a config file. You can also call sy init <plugin> to initialize a skeleton config file, e.g. sy init ftp for the FTP plugin (the setup for other plugins works exactly the same). Before doing anything else, you can/must edit the config file using your favorite editor, e.g. vi .syncany/config.json. After editing, the file should look something like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
{ "machineName": "wonderlandalice7571283", "connection": { "type": "ftp", "settings": { "hostname": "ftp.aliceandbobsftpserver.com", "username": "ftpuser", "password": "ftppass" "path": "/repo1" } }, "encryption": { "enabled": true, "pass": "supersecuresymmetricpassword" } } |
If you want to use the same repo on another machine, simply do the same for the second user/machine (here: Bob), and make sure that the ‘machineName’ is different. Once you’ve done that, you can start syncing!
|
1 2 3 4 5 |
alice@wonderland:~/Syncany$ echo "Milk and Cookies" > shoppinglist.txt alice@wonderland:~/Syncany$ sy status ? shoppinglist.txt alice@wonderland:~/Syncany$ sy up alice@wonderland:~/Syncany$ |
Bob can now download the changes and also upload files:
|
1 2 3 4 5 |
bob@thebuilder:~/Syncany$ sy ls-remote ? db-wonderlandalice7571283-1 bob@thebuilder:~/Syncany$ sy down bob@thebuilder:~/Syncany$ ls shoppinglist.txt |
If you’re having trouble with the code, please do let me know, but remember that we’re still heavily developing and everything might change.
4. Future plans and upcoming releases
Having explained the details on how we got here and where we stand, let’s get into details about where we are going.
In short, I am still planning to release Syncany as open source and I am very confident that the release is not far away anymore. However, in order to not make the same mistakes again (see above!), I don’t want to announce anything until I am sure that the code is at least somewhat stable — meaning that I’d feel comfortable synchronizing files with it, and that I’ve done that for a few days/weeks. At this very moment, this is not yet the case — there are frequently popping up new and unexpected cases in which the synchronization fails. However, as said above, I can see the light …
As soon as the “day of light” has come, the current plan is to not release a first version to the broad public, but to “silently” release it to the people that have been interested in Syncany and the people that have been following the project — namely the Launchpad community and the people who wrote me e-mails about it. Of course the code will be online and available for everybody!
While I’m not promising anything, my current plan is to release something by the end of the year — nothing stable, just a developer preview of the command line client!
5. Outlook on the next posts
This post is only the first part of a few posts I am planning to write about Syncany. In the second post, I’ll go into details of the inner workings of Syncany as of now. That’ll probably include topics such as the synchronization mechanisms, the database structure, the chunking framework, the encryption and the connection/transfer plugins. I’ll also probably publish a screencast/video of what Syncany can do so far. So stay tuned!
If you have any questions, fire away in the comments section below, fork me on Github, or ask stuff on the Launchpad mailing list.
Update (14 Feb 2014): I finally got around to writing the follow-up blog post to this one (part 2). Check out Deep into the code of Syncany – command line client, application flow and data model (part 2).
Good to hear that this awesome project is still running. Thanks for the update. Keep us posted!
Really fantastic job so far! Looking forward to getting Syncany on mac and windows platforms.
Keep working!
We’re waiting for Syncany since the beginning.
Great to know, you’re still working on it.
Keep us informed, please ;)
To be honest, I had given up.
More than many thanks for proving me wrong!
Hello Roger,
believe me, for a while I had too. After all, I am basically re-writing many parts of a version control system from scratch, but with a lot more constraints. But as I said above: I can see the light! It’s all coming together.
Thanks for staying put.
Best,
Philipp
Have you considered crowdsourcing some funds to develop the project faster? Mailpile raised $150k+ after the NSA debacle (http://www.indiegogo.com/projects/mailpile-taking-e-mail-back). This project might get the same kind of attention and I would definitely support it if someday it means I can have a Dropbox-like tool but cheaper and under my control ;)
Right now I’m using Bittorent Sync on my devices. It is functional but not as powerful as Dropbox yet.
Haven’t really thought about that up until now. But I will surely look into that :-D
Hallo,
das ist unglaublich, dass das Projekt noch lebt. Ich bin begeistert. Habe über die Jahre mindestens ein Mal im Monat den Bookmark angeklickt und jetzt sehe ich das es Syncany noch gibt. Das freut mich. Viel Erfolg weiterhin.
Gruß
Marko
Keep up the good work! I’ve been waiting so long for an update on this project.
Glad to hear you are still excited about it. It is still a great idea. I think the crowd sourcing idea would work well. Get a little press time and it will take off.
Not sure press time is the best thing right now. That was part of the reason it tanked last time. Too much attention with too little to show for. Then again, with crowdfunding people don’t expect you to have something to show for…
I’ll definitely think about it!
I think you need to find more developers to jump into this project. A one man show can’t handle a project like this all alone if we want a good open source, self-hosted solution which is as easy to use as Dropbox an Co. Phil, are you in contact with other developers? I’m not a developer, but I think networking with other interested devs + crowdfunding is the key to get this thing alive so that also noobs can use this service.
Hello Michael,
believe me I know that one person cannot develop a quality application, but it’s incredibly hard to find people that are willing to invest as much of their spare time as is necessary to understand and contribute to the core application.
I have talked to countless people and explained the architecture to so many people and most of the time, the reaction is something like “that’s a great project, but I don’t have the time/skills/experience/…”. As described in the post, the main problem is that it combines so many different technologies and concepts — and that’s hard to grasp if you’re new to the project. It takes significant effort to understand it fully. So far I have found only one person (Steffen Dangmann) who has taken the time to understand the whole thing and is now able to make significant contributions. Steffen and I meet once or twice a week and talk about the implementations before we actually code anything.
That’s exactly why I am currently documenting lots of things in lots of different ways to make it easier for people to understand and join in. Just yesterday, I finished making a sequence diagram that shows Syncany’s core operations: https://github.com/binwiederhier/syncany/blob/1731743a9b76903c1580c96139c71b0bc3a702b3/docs/Diagram%20Application%20Flow%202.pdf?raw=true
Eventually, we’ll be able to bring in more people and then it’ll take off — at least that’s what I hope it’ll do :-)
Best, Philipp
Hi,
I’m glad to hear news about syncany. I really though the project was dead. Unfortunately, I don’t have so much time to offer due to my studies and my job. But I will try to help if I can. I will start by run the program and have a look at the source code.
Cheers
Gaétan
Hi Gaétan, glad to hear that you’re still on board! Best, Philipp
Hi Phillip,
I’m glad to read that you’ve not abandoned the project as in my opinion, it has an enormous potential. It sort of feels the gap between unison (http://www.cis.upenn.edu/~bcpierce/unison/) and git annex (http://git-annex.branchable.com/) by adding some versioning (and not full versioning which is in my opinion overkill in many situations) and encryption to unison like synchro. I’ve started to look at the current code and if I find some time, I might try to contribute. I know you received my similar offers, that’s why I’m prudent :-)
Meanwhile, I’ve a question: is the notion of file modification content and attributes based, as in unison/git, or do you rely on modification times? I like the unison approach of using the inode number and the mtime in order to detect when it has to consider the file for a content modification and I think it would be nice to have that in Syncany (via the fileKey method of BasicFileAttributes, if I’m not mistaken).
Best,
Fabrice
Hello Fabrice,
whenever you have the time, feel free to ask/contribute. We need people like you!
The StatusOperation (find locally changed files) uses the FileVersionComparator to compare a local file to its database representation. It does not use file keys or inode numbers, but rather compares size, last mod. date and file attributes. If the option --force-checksum is used, a checksum comparison is enforced (if size and last mod. date are equal).
In most cases, last mod. date and size are enough to detect changes. Only in situations in which changes happen really fast and do not change the size of a file, a checksum comparison (or file key / inode comparison) is helpful. A situation like this is for instance the unit tests.
At a later stage, we could use inode comparisons, but for now, the above described approach is enough and very reliable. The thing that’s stopped me from implementing the inode-based comparison is that you would have to store the file keys locally — and since we do not (yet) have an actual SQL-database, storing stuff is always a pain :-)
Best regards,
Philipp
Thanks for the answer Philipp (and sorry for misspelling your name, by the way :-(
Just to be sure, it seems that you are implementing something close to Unison’s semantic for local change detection, i.e., walk the filesystem and record in a local database a kind of signature of each file (size, last mod. date, whatever).
The trick used by Unison (apart from the inode thing) is to have a local database on each “root” (in Unison’s parlance) and no central database (as there is no central node per se). So when A tries to sync with B, each root computes its local list of modifications and if they collide, Unison reports the collisions and that’s all (non concurrent modifications are synced on each side, but that’s the easy part). It’s both a blessing and a curse of Unison: its automatic conflict resolution methods are quite limited in practice, but it has also a very clear semantic.
So I’m wondering how you plan to handle concurrent modifications and a possibly central database? Let’s say the central repository (C) has file f. A and B get file f and make concurrent modifications. A syncs before B and pushes to C a file f with last modifications at time t. B did its modifications before A (at time t-1) but pushes after. In the Unison case, there is a concurrent modification detection, because C has a database share with A and _another_ database shared with B. So regardless of the modification time, trying to push from B will be detected as a conflict (which is nice!). What do you plan to do about that in Syncany? This is an important use case for mobile workers (like me). I sometimes forget to sync my computer A (this might be also caused by a connectivity problem) with C. Then I work on B and also forget to sync (again this can be caused by connectivity problems). Next iteration has me syncing A and then trying to sync B. I don’t want B’s modifications of f to be silently pushed as an earlier version of f. (that would be original f, B’s f and then A’s f). And also, I would feel very uncomfortable if the ordering of versions were to be based on comparisons of modification dates for different machines.
I hope I’m clear enough and if you planned to address those aspects in a future blog post, I’ll be glad to read it then rather than right now :-)
Best,
Fabrice
PS: what kind of local storage do you plan in the future?
Hello Fabrice,
don’t worry about mis-spelling my name — that happens all the time :-)
You are right, this is a tricky situation and it will occur many many times. But luckily I have made so many mistakes with Syncany in earlier incarnations/implementations that I believe we actually got it right this time.
I’ll briefly explain it here and in a long version in the second blog post I’m writing. Here is how it works: Each “up” gathers local changes and groups them together in a “database version” (~ commit). A database version is identified by a vector clock and a local timestamp. The sync algorithm (in “down”) first uses vector clocks to compare database versions, and if a conflict occurs (= two concurrent/simultaneous vector clocks), it uses the lowest (= earliest) local timestamp to determine the winner.
Case 1: If, like in your example, two clients A and B push to C at different times (let’s assume first A, then B), B will complain about unapplied/unknown remote changes and never let you upload anything. You’ll have to call “down” first to resolve this issue. The “down” operation will then detect that your local file is not the expected file (because you have changed it!), and would create a locally conflicting file (like Dropbox: “file 1 (Fabrice’s conflicting version).txt”).
Case 2: If the two clients A and B push their changes at the exact same time (assuming A uploads a few milliseconds earlier), they would both upload their changes. As soon as they call “down” for the next time, they analyze the other client’s changes and compare the vector clocks of the first conflicting database version. Because they are simultaneous (= based on the same database version, but committed independently), they both compare the local timestamp of the database version and both come to the same conclusion: A wins by a few milliseconds. A does nothing, because it wins, and B applies A’s changes locally. If any of the local files do not match the expected version (as per the local database), a conflicting file (like above) is created.
This sounds complicated (and it is), but it’s already implemented and works pretty stable. I’ll record a small video to show you….
Best,
Philipp
There you go: https://www.youtube.com/watch?v=tvsZcuhVH8c
Thanks a lot Philipp for the explanations and the screencast! I did not know the vector clock concept, even though I’m familiar with related concepts (such as Lamport timestamps). I’ve read yesterday your master’s thesis about Syncany and I was wondering how much you changed the core concepts from it. In particular, you wrote about local history, a concept which sounds quite related to what you just exposed, but you kind of imply above that you changed things here.
Best,
Fabrice
Well the master’s thesis mainly describes the chunking and multichunking concepts — this has not changed much. The chunking parts are the most stable parts of all.
Let’s see about the rest:
I’ll write a lot about that in the next blog post. So be patient :-D
In case you did not see it under the video: I uploaded the resulting files from the screencast. Especially the database in clientA/.syncany/db/local.db explains a lot about the internal structure.
Hi Philipp! I’m very happy to hear from you that Syncany project is not dead!
I’m following the project through Twitter and, in fact, I didn’t see any changes in the last two years even if the screenshots you did in 2011 were very very promising!
It’s not a simple architecture but I think you are now on the right way.
In these days I’m reading The Cathedral and The Bazaar (http://en.wikipedia.org/wiki/The_Cathedral_and_the_Bazaar) and I want you to share with you just few thoughts that you can find useful for your big challenge:
1. Given a large enough beta-tester and co-developer base, almost every problem will be characterized quickly and the fix obvious to someone. (the point 8 in the original book)
2. If you treat your beta-testers as if they’re your most valuable resource, they will respond by becoming your most valuable resource. (the 10th)
3. The next best thing to having good ideas is recognizing good ideas from your users. Sometimes the latter is better. (the 11th)
Remember the importance of re-writing and re-design your software, it’s a very honest acknowledgment from you and the symptom of smart developers!
Remember the importance of a growing and passionated community around your project, it will help you write code, plugins and test all of them!
So, IMHO, maybe it’s not yet time to increase too much the working group but keep in mind that maybe the community around the project will be the future for the project itself.
ROb
Hi Philipp,
I didn’t realize SyncAny was still in development! Do you want to talk about teaming up? I’m the lead developer of IQBox, which is a free, open-source sync tool. Currently supporting FTP-SSL and Windows. Support for Linux and Mac are not officially released until Feb. 2014 but are working in the lab. We will add more backends later (Amazon S3, SFTP). It’s in alpha, but stable and usable:
https://code.google.com/p/iqbox-ftp/
Screenshot 1: Login Screen:
http://goo.gl/eMha3D
Screenshot 2: Upload Progress:
http://goo.gl/Ois7XS
I think working together makes sense. I have 2 other programmers committed to the project, and some specialists in Linux to help with making a proper Linux installer (which in itself is a huge task). Because it’s a pet project of a profitable company (IQ Storage) we can afford to pay a few full-time coders.
The code of each project so far might not be the same, but this is a long-term, multi-year project, so the long-term benefits of collaboration might outweigh our setbacks.
Let me know your thoughts.
Hello Simon,
looks like your main focus is on synchronization with FTP. Do you have plans (or maybe implemented) encryption and versioning?
We can surely talk about it. Feel free to chat me up on Hangouts or Skype.
Best,
Philipp
Hi Philipp,
Great to hear back. I sent you a message on Google Hangouts with my contact info.
Yup, we do have plans to implement local encryption and versioning. (It currently supports FTP-SSL by default. That’s in-transit encryption. Ideally files would be encrypted at-rest too.)
Hi Philipp,
First thanks for this great project. I heard of it 1 year ago and read your master thesis but the development looks kind of dead at this moment, I am happy about the regain of activities !
I would like to work on a p2p abstraction for syncany.
Here is some use cases I would like to see working and some problems to solve :
1) no central repository.
The clients will have to negotiate with each other to find which one is the “master”. According to the current infra it looks like the db is now fully incremental, so the client with the most recent (or the most ?) db files is the master ?
The db is incremental, but is it independently incremental ?
if 2 clients have modified their db independently, does the db merge is only a matter of retrieving both added db files and put it in a single repo ? If not is it easily implementable ?
2) central repository.
In this case the client should look for other clients on the same network only to optimize bandwith.
I think db files should systematically be fetched from the central repo if available (otherwise fallback case 1) and then data chunks are download with local peers (with fallback on repo if nobody is available).
transversal known p2p problems :
– discovery and notification of peers (use stacksync or SparkleShare derived implementation ?). For local network I think broadcast should be used. For internet a central server is needed (long term goal).
A unique repo identifier is needed to globally identify a repo.
There is a lot of activities on open source dropbox-like client-side encrypted softwares right now, and I hope they will quickly converge.
Syncany seems to be a winner regarding the core part, SparkleShare uses git which is great but inefficient with binaries.
Side note :
I am currently working on a storage implementation for my isp box (freebox), which has a rest api available. I implement most of it in an independent LGPL library now available on github.
Is there a way to depend on it without publishing the lib in maven repositories ?
Regards
Hi Mathieu,
thanks for the great comments. That’s a lot of stuff you commented on, and I think I’ll have re-establish or revive the mailing list for further discussions. Now to your comments:
General comments: Syncany’s architecture already is decentral with regards to negotiation of the “winner” (= “master”) of an update. All clients discover and download new database files, analyze them and come to the same conclusion. This comparison is based on vector clocks.
With regard to the storage, however, Syncany’s plugins currently only implement centralized backends. All you have to do to make a decentral storage backend is to implement a decentral backend, right?! Having a DHT as a backend would already work, because a DHT implements the same methods that are needed for Syncany’s plugins: connect/disconnect/upload/download/list/delete.
To question 1) The database files are incremental per client, but they depend on each other. A database file can contain 1-n database versions, each of which is identified by the a vector clock and a local timestamp. When two clients upload a file at the same time, each of them writes a corresponding database version (increment) in a new database file (e.g. db-A-2 and db-B-3). They both download the new files of the other client and compare the vector clocks. If they are in conflict (= simultaneous), the oldest timestamp wins. The losing database file is ignored until the loser merges his changes and uploads a new non-conflicting database.
So as said above: This already is decentral behavior, but based on a central dumb storage. Does that answer your question?
To question 2) Implementing LAN sync is veeery low on the TODO-list as you might have guessed. If you’d like to implement it, go for it :-)
Discovery / Repo ID: I like the SparkleShare model. They use a central pub/sub server based on fanout to notify other clients. In fact, I implemented this yesterday in the “announcements” branch. It is used in the watch operation: It subscribes to a channel <repo-id> and announces updates when local updates occur (UpOperation uploaded changes). When a push notification is received from the repo-id channel, the local sync is started. You can try it: sy watch --debug --announcements=notifications.sparkleshare.org:443
Combining these push notifications with a local file system watcher leads to instant updates! And of course the pub/sub system could also be used to exchange (encrypted) messages between clients.
Regarding your github-question, I don’t think I can help you, sorry …
Please feel free to contact me (also via e-mail). If you’re interested in helping out, we should exchange mails or talk via Skype!
Best regards,
Philipp
Hi Phillip,
Thanks for your answer.
I have some time available in the next month and I am willing to work on Syncany.
My java background is quite solid, and I am highly interested in network related topics, even if my background on that is mostly theorical.
Regarding all my p2p questions, I don’t know if you have heard about bittorrent sync :
http://www.bittorrent.com/intl/fr/sync/technology
The tech looks awesome, unfortunatly this is not open source, the protocol is undocumented and they seem to rely on the clients (hence servers) being trustworthy, since they have the secret.
Here are the main points of bittorrent sync that I am interested about :
– read only mode. To handle that I guess we need to have :
a read only token which can be the current encryption/decryption key
a write token which should be used to sign (meta?)data. I think signing metadata is enough since if the metadata is considered trusted the data can then be considered trusted thanks to data hashes stored in metadata.
This would lead to 3 needed token for a repo : one public for identification on the network so that fully untrusted (p2p) storages can be used, one secret for encryption/decryption and one for signing.
– “one time” access mode. I don’t see how they can do that without basically creating a new repo with a copy of the data decrypted & encrypted with a new key : it would need a trustworthy client as a proxy which have the decryption key to do that. Perhaps allowing more than one repo on storages would be usefull so we can share things with untrusted people using the same storage. Writing back changes to the “master” repo would then need a validation of a client.
– fully decentralized mode possible. Like you said previously it should be doable with the current architecture by implementing a dht storage. I took a look at the various java p2p implementations available and tomP2P seems really great. It already handles nat travesal using upnp and nat-pmp, and ICE is planned.
However I am unsure about storing the data itself in the DHT, perhaps metadata should be enough and data could be exchanged directly between clients (looks easily doable with tomp2p too).
Regarding having a dropbox/ftp as a fallback (not really master) the client asking for changes could register the dropbox/ftp abstraction as a p2p client which would then be treated as any other client.
On a sidenote a mailing or something like that would be great to exchange ideas. Or perhaps we can just open an issue on github ?
Hello again Mathieu,
this is a really interesting topic, although I wouldn’t say it’s going to be my main focus for any time soon. If you’re interested in discussing this, however, I am always open to do so. I’d suggest you sign up to the mailing list: It’s unfortunately still on Launchpad, since Github doesn’t have mailing lists.
Here’s the link: https://launchpad.net/~syncany-team
Archive here: https://lists.launchpad.net/syncany-team/
I think it’s best if you re-post this on the mailing list and I’ll answer you there, so everyone can see this. Is that okay for you?
Also, please take note of our new roadmap: https://github.com/binwiederhier/syncany/wiki
Best,
Philipp